Small strings in Rust
- Scaffolding
- Parsing a JSON data set
- Profiling memory allocations
-
The
reportsubcommand - As few allocations as possible
-
The
smol_strcrate -
The
smartstringcrate - Let's summarize
Contents
Hey everyone!
This article is brought to you by a shameless nerd snipe, courtesy of Pascal.
In case you've blocked Twitter for your own good, this reads:
There should be a post explaining and comparing smolstr and smartstring (and maybe others, like smallstr)
Well, I took the bait.
But, since this is me writing, I get to set the rules:
- There will be no "maybe others" - we'll review just the first two
- We're going to allow ourselves at least three digressions.
Let's get started - there is much to do.
$ cargo new small
Created binary (application) `small` package
Scaffolding
Our little crate is going to go places, so I want to set up a few things
ahead of time - I'm going to use argh to parse arguments.
$ cargo add argh
Adding argh v0.1.3 to dependencies
And I'm going to set up subcommands - for now, we'll only have one,
named sample. It's going to go into its own module.
// in `src/main.rs`
pub mod sample;
use argh::FromArgs;
#[derive(FromArgs)]
/// Small string demo
struct Args {
#[argh(subcommand)]
subcommand: Subcommand,
}
#[derive(FromArgs)]
#[argh(subcommand)]
enum Subcommand {
Sample(sample::Sample),
}
impl Subcommand {
fn run(self) {
match self {
Subcommand::Sample(x) => x.run(),
}
}
}
fn main() {
// see https://turbo.fish/
argh::from_env::<Args>().subcommand.run();
}
// in `src/sample.rs`
use argh::FromArgs;
#[derive(FromArgs)]
/// Run sample code
#[argh(subcommand, name = "sample")]
pub struct Sample {}
impl Sample {
pub fn run(self) {
todo!()
}
}
Let's try it out:
$ cargo run -- sample
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/small sample`
thread 'main' panicked at 'not yet implemented', src/sample.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Wonderful. That's all we need for now.
Parsing a JSON data set
Our task for today is going to be: parsing a list of the 1000 largest US cities from a JSON file.
If you're following along, download that gist to a file named cities.json
directly into the small/ folder.
serde and serde_json are going to make this task very easy.
# in Cargo.toml
[dependencies]
argh = "0.1.3"
# these two are new:
serde = { version = "1.0.114", features = ["derive"] }
serde_json = "1.0.56"
The dataset contains a lot of information, including population growth, geographic coordinates, population, and rank. We're only interested in the city name, and the state name.
// in `src/sample.rs`
impl Sample {
pub fn run(self) {
self.read_records();
}
fn read_records(&self) {
use serde::Deserialize;
#[derive(Deserialize)]
struct Record {
#[allow(unused)]
city: String,
#[allow(unused)]
state: String,
}
use std::fs::File;
let f = File::open("cities.json").unwrap();
let records: Vec<Record> = serde_json::from_reader(f).unwrap();
println!("Read {} records", records.len());
}
}
$ cargo run -- sample
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Running `target/debug/small sample`
Read 1000 records
Fantastic. That was easy!
Profiling memory allocations
I'm interested in how much memory our program is using, and also how many allocations and deallocations it does.
We've used the Massif tool (from the Valgrind suite) in Abstracting away
correctness, to demonstrate a
bug in Go's runtime/pe package.
But today I feel like trying something a little different.
Something a little more ad hoc. A little more fun.
We're going to make a tracing allocator.
Well, to start with, we're just going to wrap the system allocator.
// in `src/main.rs` pub mod alloc;
// in `src/alloc.rs`
use std::alloc::{GlobalAlloc, System};
pub struct Tracing {
pub inner: System,
}
impl Tracing {
pub const fn new() -> Self {
Self { inner: System }
}
}
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
self.inner.alloc(layout)
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: std::alloc::Layout) {
self.inner.dealloc(ptr, layout)
}
}
All of this is in Rust stable, by the way.
Why does GlobalAlloc require an unsafe impl?
It's not only unsafe to call its methods, it's unsafe to implement the trait itself. The documentation mentions "several reasons", among which:
It's undefined behavior if global allocators unwind. This restriction may be lifted in the future, but currently a panic from any of these functions may lead to memory unsafety.
Luckily, in Rust, undefined behavior is confined to well-identified unsafe
sections, and this is no exception.
Now that we've got a custom allocator, all we need to do is use it:
// in `src/main.rs` #[global_allocator] pub static ALLOCATOR: alloc::Tracing = alloc::Tracing::new();
See how this is a static, and yet we're calling a function?
That's because it's a const fn - which are stable since Rust 1.31.
As of 1.44, there's still restrictions on what you can do inside const fns.
For example, Default::default() is not const fn, and neither is
Into::into().
Does everything still work?
$ cargo run -- sample
Compiling small v0.1.0 (/home/amos/ftl/small)
Finished dev [unoptimized + debuginfo] target(s) in 1.73s
Running `target/debug/small sample`
Read 1000 records
Yes. Good.
We'd like our tracing allocator to say something, if they see something.
But this is easier said than done.
If we try to use println!:
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
println!("allocating {} bytes", layout.size());
self.inner.alloc(layout)
}
// etc.
}
$ cargo run -- sample
Compiling small v0.1.0 (/home/amos/ftl/small)
Finished dev [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/small sample`
^C
...it hangs forever. Both in debug and release builds (I checked).
Where does it hang?
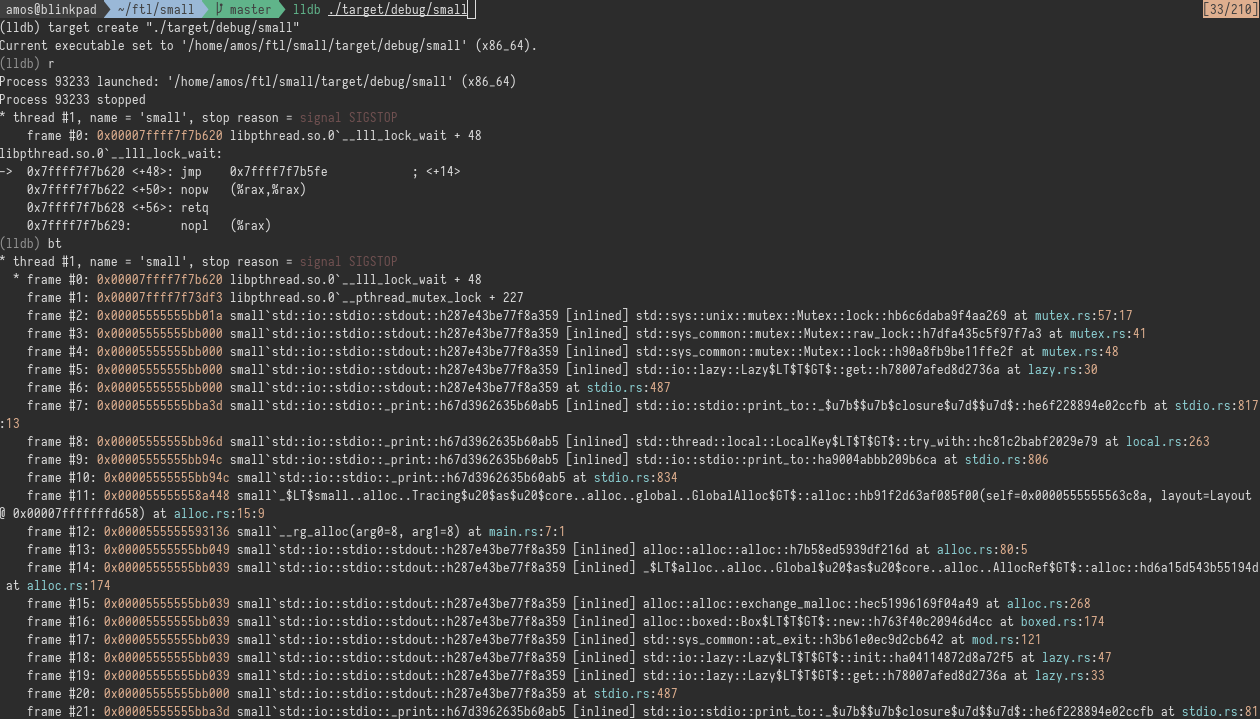
..while trying to acquire a lock on stdout.
Let's bypass Rust's standard output machinery:
$ cargo add libc
Adding libc v0.2.71 to dependencies
Now, one very important thing to keep in mind when writing a custom allocator, is that... we can't allocate any memory. Well, we can - but if we're not careful, and we put some values on the heap by accident, the allocator will end up calling itself, and then we'll have a stack overflow.
So this, for example, doesn't work:
// in `src/alloc.rs`
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
let s = format!("allocating {} bytes", layout.size());
libc::write(libc::STDOUT_FILENO, s.as_ptr() as _, s.len() as _);
self.inner.alloc(layout)
}
// etc.
}
We all like type inference, right?
Turns out, you don't need to spell out as u64, or as usize, or as f64. If
the compiler can infer it, just use as _!
$ cargo run -- sample
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/small run`
[1] 94868 segmentation fault (core dumped) cargo run -- run
...because format! ends up allocating memory - if only for the resulting
String.
This however, is fine:
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
let s = "allocating!\n";
libc::write(libc::STDOUT_FILENO, s.as_ptr() as _, s.len() as _);
self.inner.alloc(layout)
}
// etc.
}
$ cargo run -- sample | head
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Running `target/debug/small sample`
allocating!
allocating!
allocating!
allocating!
allocating!
allocating!
allocating!
allocating!
allocating!
allocating!
(cut off by '| head')
But it's not very helpful. Here's an idea - how about we write out
one JSON object per line on stderr? I don't think serde_json needs
to heap-allocate when serializing objects, so we should be in the clear.
Let's make an enum with two variants:
// in `src/alloc.rs`
use serde::{Deserialize, Serialize};
#[derive(Clone, Copy, Serialize, Deserialize)]
pub enum Event {
Alloc { addr: usize, size: usize },
Freed { addr: usize, size: usize },
}
Then two helpers so we can write those events to stderr easily:
// in `src/alloc.rs`
use std::io::Cursor;
impl Tracing {
fn write_ev(&self, ev: Event) {
let mut buf = [0u8; 1024];
let mut cursor = Cursor::new(&mut buf[..]);
serde_json::to_writer(&mut cursor, &ev).unwrap();
let end = cursor.position() as usize;
self.write(&buf[..end]);
self.write(b"\n");
}
fn write(&self, s: &[u8]) {
unsafe {
libc::write(libc::STDERR_FILENO, s.as_ptr() as _, s.len() as _);
}
}
}
And use them in our alloc and dealloc function to write the
corresponding events:
// in `src/alloc.rs`
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
let res = self.inner.alloc(layout);
self.write_ev(Event::Alloc {
addr: res as _,
size: layout.size(),
});
res
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: std::alloc::Layout) {
self.write_ev(Event::Freed {
addr: ptr as _,
size: layout.size(),
});
self.inner.dealloc(ptr, layout)
}
}
$ cargo build && ./target/debug/small sample 2>! events.ldjson
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Read 1000 records
$ head -3 events.ldjson
{"Alloc":{"addr":93825708063040,"size":4}}
{"Alloc":{"addr":93825708063072,"size":5}}
{"Freed":{"addr":93825708063040,"size":4}}
We can no longer use cargo run, otherwise cargo's own output
would end up in events.ldjson.
Also, Amos is using zsh here, that's why he has to use 2>! instead
of just 2>. The ! tells zsh to overwrite the file if it exists.
By default it would just refuse to write to it.
There's one last thing our custom allocator needs: an on and off switch.
Right now it reports every allocation, from the very start of our program, including argument parsing. This isn't much compared to the JSON parsing phase, but it's still something I'd like to exclude from our measurements.
So, let's add a switch:
// in `src/alloc.rs`
use std::sync::atomic::{AtomicBool, Ordering};
pub struct Tracing {
pub inner: System,
// new
pub active: AtomicBool,
}
impl Tracing {
pub const fn new() -> Self {
Self {
inner: System,
active: AtomicBool::new(false),
}
}
pub fn set_active(&self, active: bool) {
self.active.store(active, Ordering::SeqCst);
}
}
unsafe impl GlobalAlloc for Tracing {
unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
let res = self.inner.alloc(layout);
if self.active.load(Ordering::SeqCst) {
self.write_ev(Event::Alloc {
addr: res as _,
size: layout.size(),
});
}
res
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: std::alloc::Layout) {
if self.active.load(Ordering::SeqCst) {
self.write_ev(Event::Freed {
addr: ptr as _,
size: layout.size(),
});
}
self.inner.dealloc(ptr, layout)
}
}
The allocator will start off inactive, and we can activate it just for our JSON workload:
// in `src/sample.rs`
impl Sample {
fn read_records(&self) {
// omitted: `struct Record`
use std::fs::File;
let f = File::open("cities.json").unwrap();
crate::ALLOCATOR.set_active(true);
let records: Vec<Record> = serde_json::from_reader(f).unwrap();
crate::ALLOCATOR.set_active(false);
println!("Read {} records", records.len());
}
}
$ cargo build && ./target/debug/small sample 2>! events.ldjson
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Read 1000 records
$ grep 'Alloc' events.ldjson | wc -l
2017
$ grep 'Freed' events.ldjson | wc -l
16
But grep and wc aren't the best we can do to analyze those events.
Let's build something a little comfier.
The report subcommand
Let's add another subcommand, also in its own module:
// in `src/main.rs`
pub mod report;
#[derive(FromArgs)]
#[argh(subcommand)]
enum Subcommand {
Sample(sample::Sample),
Report(report::Report),
}
impl Subcommand {
fn run(self) {
match self {
Subcommand::Sample(x) => x.run(),
Subcommand::Report(x) => x.run(),
}
}
}
Here's my wishlist. I would like:
- To measure peak memory usage
- Along with total allocations and deallocations
- To format sizes as B, KiB, etc.
- To have a nice little graph of memory usage, just like Massif does
Alright then, let's go shopping.
$ cargo add bytesize
Adding bytesize v1.0.1 to dependencies
$ cargo add textplots
Adding textplots v0.5.1 to dependencies
That's it? Are we saving our crate budget for something else?
Nope, that's all we need.
Hold on a second, I have a question: why are we first saving events to a file, and later analyzing it with another subcommand?
Couldn't we just do everything in one run?
We probably could! But that way, the code is simpler. It would probably be tricky to collect events in-memory without doing any heap allocations.
We would have to:
- Allocate a fixed-size buffer ahead of time, either in static storage, or on the heap but using the system allocator directly.
- Make sure we handle synchronization properly -
GlobalAlloconly requires&selfforallocanddealloc, so we'd have to do our own locking
And locking hasn't worked great for us so far (see the println! debacle).
So, that way is simpler! A bit more annoying to use, but simpler.
Fair enough, carry on.
The reporter is fairly simple. It simply parses each line as a JSON record
of type crate::alloc::Event, using serde_json. Then it goes through each
record, keeps track of the current of amount of memory used, and peak usage,
and builds a series of (f32, f32) for textplots.
Let's go:
// in `src/report.rs`
use crate::alloc;
use alloc::Event;
use argh::FromArgs;
use bytesize::ByteSize;
use std::{
fs::File,
io::{BufRead, BufReader},
path::PathBuf,
};
use textplots::{Chart, Plot, Shape};
#[derive(FromArgs)]
/// Analyze report
#[argh(subcommand, name = "report")]
pub struct Report {
#[argh(positional)]
path: PathBuf,
}
trait Delta {
fn delta(self) -> isize;
}
impl Delta for alloc::Event {
fn delta(self) -> isize {
match self {
Event::Alloc { size, .. } => size as isize,
Event::Freed { size, .. } => -(size as isize),
}
}
}
impl Report {
pub fn run(self) {
let f = BufReader::new(File::open(&self.path).unwrap());
let mut events: Vec<alloc::Event> = Default::default();
for line in f.lines() {
let line = line.unwrap();
let ev: Event = serde_json::from_str(&line).unwrap();
events.push(ev);
}
println!("found {} events", events.len());
let mut points = vec![];
let mut curr_bytes = 0;
let mut peak_bytes = 0;
let mut alloc_events = 0;
let mut alloc_bytes = 0;
let mut freed_events = 0;
let mut freed_bytes = 0;
for (i, ev) in events.iter().copied().enumerate() {
curr_bytes += ev.delta();
points.push((i as f32, curr_bytes as f32));
if peak_bytes < curr_bytes {
peak_bytes = curr_bytes;
}
match ev {
Event::Alloc { size, .. } => {
alloc_events += 1;
alloc_bytes += size;
}
Event::Freed { size, .. } => {
freed_events += 1;
freed_bytes += size;
}
}
}
Chart::new(120, 80, 0.0, points.len() as f32)
.lineplot(Shape::Steps(&points[..]))
.nice();
println!(" total events | {}", events.len());
println!(" peak bytes | {}", ByteSize(peak_bytes as _));
println!(" ----------------------------");
println!(" alloc events | {}", alloc_events);
println!(" alloc bytes | {}", ByteSize(alloc_bytes as _));
println!(" ----------------------------");
println!(" freed events | {}", freed_events);
println!(" freed bytes | {}", ByteSize(freed_bytes as _));
}
}
Shall we give it a try?
$ cargo build && ./target/debug/small sample 2>! events.ldjson && ./target/debug/small report events.ldjson
Finished dev [unoptimized + debuginfo] target(s) in 0.09s
Read 1000 records
found 2033 events
⡁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⡏ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⡁ 82670.0
⠄ ⡇ ⠄
⠂ ⡇ ⠂
⡁ ⡇ ⡁
⠄ ⡇ ⣀⣀⣀⣠⠤⠤⠤⠖⠒⠒⠚⠉⠉⠉⠅
⠂ ⡇⣀⣀⣀⣠⠤⠤⠤⠖⠒⠒⠚⠉⠉⠉⠁ ⠂
⡁ ⡏⠁ ⡁
⠄ ⡇ ⠄
⠂ ⡇ ⠂
⡁ ⡇ ⡁
⠄ ⡇ ⡇ ⠄
⠂ ⡇ ⡇ ⠂
⡁ ⡇⣀⣀⣀⣀⡤⠤⠤⠴⠒⠒⠒⠋⠉⠉⠁ ⡁
⠄ ⡏⠁ ⠄
⠂ ⡇ ⠂
⡁ ⢸ ⡇ ⡁
⠄ ⢸⠴⠒⠒⠒⠚⠉⠉⠁ ⠄
⠂ ⢠ ⢸ ⠂
⡁ ⢀ ⢸⠒⠋⠉⠉ ⡁
⢄⣰⠼⠉⠉ ⠄
⠉⠉ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁ 1.0
0.0 2033.0
total events | 2033
peak bytes | 82.7 KB
----------------------------
alloc events | 2017
alloc bytes | 115.8 KB
----------------------------
freed events | 16
freed bytes | 49.2 KB
How fascinating! You can see that the line goes way up and falls back down almost immediately at several points.
My theory is pretty simple: it's reading a thousand records into a Vec. But
since everything is streaming, it has no idea what capacity to reserve for
the Vec.
When it grows, the Vec must first allocate new_capacity bytes, then copy
over from the old storage, and only then can it free the old storage.
So the peaks we see are almost definitely Vec resizes.
We can also see that between those peaks, memory usage increases steadily -
each String stores its data on the heap, which explains the number of
allocation events, 2017.
As few allocations as possible
Now that we can read our JSON file into Rust data structures, and we can profile allocations, let's think about reducing the number of allocations.
Why? Because the fastest code is the code you don't execute. If you do fewer allocations, then you're spending less time in the allocator, so you should see a performance boost.
Unless you're achieving "fewer allocations" by doing a lot more work, which would be a different compromise - but one that is still worth doing in some cases.
In our case, our input file is relatively small (in terms of a contemporary desktop computer), so we can afford to read it all in memory in one go.
And if we do that, we can deserialize to &str rather than String, if
we tell serde to borrow from the input.
// in `src/sample.rs`
impl Sample {
pub fn run(self) {
self.read_records();
}
fn read_records(&self) {
use serde::Deserialize;
#[derive(Deserialize)]
struct Record<'a> {
#[allow(unused)]
#[serde(borrow)]
city: &'a str,
#[allow(unused)]
state: &'a str,
}
crate::ALLOCATOR.set_active(true);
let input = std::fs::read_to_string("cities.json").unwrap();
let records: Vec<Record> = serde_json::from_str(&input).unwrap();
crate::ALLOCATOR.set_active(false);
println!("Read {} records", records.len());
}
}
Let's measure that:
$ cargo build && ./target/debug/small sample 2>! events.ldjson && ./target/debug/small report events.ldjson
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Read 1000 records
found 24 events
⡁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⢸⠉⠉⡏ ⠁⠈ ⡁ 293365.0
⠄ ⢀⣀⣀⡀ ⢸ ⠉⠉⠉ ⠄
⠂ ⢠⠤⠤⣄⣀⣸ ⠓⠒⠚ ⠂
⡁ ⢰⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠒⠚⠉⠉⠉⠉⠉ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⢸ ⠄
⠉⠉⠉⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁ 0.0
0.0 24.0
total events | 24
peak bytes | 293.4 KB
----------------------------
alloc events | 13
alloc bytes | 309.7 KB
----------------------------
freed events | 11
freed bytes | 32.7 KB
What a result!
The number of allocation events fell to 13, but peak memory usage climbed all the way up to 293 KB.
Unfortunately, bytesize defaults to powers of 1000, not 1024.
In our particular scenario, this tradeoff is perfectly acceptable - 293 KB memory usage is more than reasonable. The speed difference is going to be imperceptible, unless we do it thousands of times, but that's fine too.
However, if our dataset was much larger, we might start running into problems.
Say we ran this workload on a machine with 64 GiB of RAM - that's not atypical for a server. And say the input file was 100 GiB. We couldn't even read the whole thing in memory! We'd have to go back to a streaming solution.
And our initial streaming solution may well work - because we're only reading
out the city and state fields - not all the others, which I'm sure make
up the bulk of the 100 GiB input file.
There are other reasons why &str might not be suitable for us. We may want
to hang on to those strings, and hand them out to other parts of our program,
without worrying about lifetimes too much.
For some use cases, we may want to consider using a string interner, as a middle ground between "owned values" and "low memory usage". We're not going to review that option here.
Let's go back to our streaming solution, for the needs of the story.
The smol_str crate
The smol_str crate provides us with a
SmolStr type that has the same size as String, and stores strings of up
to 22 bytes inline. It also has special-case optimizations for strings that
are made purely of whitespace (0+ newlines followed by 0+ spaces).
It's important to note that SmolStr is immutable, unlike String. That
works well enough for our purposes.
Strings longer than 22 bytes are heap-allocated, just like the standard
String type.
But enough marketing! Let's give it a go.
Luckily, it comes with a serde feature, so we can just drop it in:
# in `Cargo.toml`
[dependencies]
# omitted: others
smol_str = { version = "0.1.15", features = ["serde"] }
In order to compare various string implementations, we'll add an option to
our sample command - parsed from an enum.
$ cargo add parse-display
Adding parse-display v0.1.2 to dependencies
// in `src/sample.rs`
use parse_display::{Display, FromStr};
#[derive(FromArgs)]
/// Run sample code
#[argh(subcommand, name = "sample")]
pub struct Sample {
#[argh(option)]
/// which library to use
lib: Lib,
}
#[derive(Display, FromStr)]
#[display(style = "snake_case")]
enum Lib {
Std,
Smol,
Smart,
}
We'll add a generic type parameter to read_records and our Record type,
so we can use whichever implementation we want:
// in `src/sample.rs`
impl Sample {
pub fn run(self) {
match self.lib {
Lib::Std => self.read_records::<String>(),
Lib::Smol => self.read_records::<smol_str::SmolStr>(),
Lib::Smart => todo!(),
}
}
fn read_records<S>(&self)
where
S: serde::de::DeserializeOwned,
{
use serde::Deserialize;
#[derive(Deserialize)]
struct Record<S> {
#[allow(unused)]
city: S,
#[allow(unused)]
state: S,
}
use std::fs::File;
let f = File::open("cities.json").unwrap();
crate::ALLOCATOR.set_active(true);
let records: Vec<Record<S>> = serde_json::from_reader(f).unwrap();
crate::ALLOCATOR.set_active(false);
println!("Read {} records", records.len());
}
}
Let's give it a go:
$ cargo build && ./target/debug/small sample --lib smol 2>! events.ldjson && ./target/debug/small report events.ldjson
Compiling small v0.1.0 (/home/amos/ftl/small)
Finished dev [unoptimized + debuginfo] target(s) in 1.82s
Read 1000 records
found 42 events
⡁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⢹⢹ ⠁⠈ ⡁ 73896.0
⠄ ⢸⢸ ⠄
⠂ ⢸⢸ ⠂
⡁ ⢸⢸ ⡁
⠄ ⢸⢸ ⠄
⠂ ⢸⢸ ⠂
⡁ ⢸⢸⣀⣀⣀ ⡁
⠄ ⢸ ⠄
⠂ ⢸ ⠂
⡁ ⢸ ⡁
⠄ ⡏⢹ ⢸ ⠄
⠂ ⡇⢸ ⢸ ⠂
⡁ ⡇⢸ ⢸ ⡁
⠄ ⡇⠘⠒⠒⠒⠒⠒⠚ ⠄
⠂ ⡇ ⠂
⡁ ⢸⢹ ⡇ ⡁
⠄ ⢸⢸⣀⡇ ⠄
⠂ ⡤⢤ ⢸ ⠂
⡁ ⢀⣀ ⡇⠘⠒⠒⠒⠒⠒⠚ ⡁
⠄ ⢀⣀⡀⢀⣀⣀⡖⠲⠤⠤⠤⠤⠤⠼⠘⠒⠃ ⠄
⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠈⠉⠉⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁ 1.0
0.0 42.0
total events | 42
peak bytes | 73.9 KB
----------------------------
alloc events | 23
alloc bytes | 98.5 KB
----------------------------
freed events | 19
freed bytes | 49.2 KB
Amazing!
Memory usage is lower than with String, and the number of allocations fell
from 2017 to just 23!
As we did before, we see peaks when the Vec resizes, but between them,
everything is flat. It seems that 22 bytes is enough to store most of the
names of the top 1000 US cities.
The smartstring crate
Can we do even better?
The smartstring crate makes similar promises
to smol_str with the following differences:
- It can inline strings of up to 23 bytes (that's one more byte!)
- Its String type is mutable
- There are two strategies, one of them re-inlines the string if a mutation makes it short enough again.
That all sounds great.
$ cargo add smartstring
Adding smartstring v0.2.2 to dependencies
It doesn't come with a serde feature at the time of this writing, but it is
pretty trivial to write an adapter.
// in `src/sample.rs`
use smartstring::{LazyCompact, SmartString};
struct SmartWrap(SmartString<LazyCompact>);
impl From<String> for SmartWrap {
fn from(s: String) -> Self {
Self(s.into())
}
}
impl From<&str> for SmartWrap {
fn from(s: &str) -> Self {
Self(s.into())
}
}
impl<'de> serde::Deserialize<'de> for SmartWrap {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
use ::serde::de::{Error, Visitor};
use std::fmt;
struct SmartVisitor;
impl<'a> Visitor<'a> for SmartVisitor {
type Value = SmartWrap;
fn expecting(&self, formatter: &mut fmt::Formatter) -> fmt::Result {
formatter.write_str("a string")
}
fn visit_str<E: Error>(self, v: &str) -> Result<Self::Value, E> {
Ok(v.into())
}
fn visit_borrowed_str<E: Error>(self, v: &'a str) -> Result<Self::Value, E> {
Ok(v.into())
}
fn visit_string<E: Error>(self, v: String) -> Result<Self::Value, E> {
Ok(v.into())
}
}
deserializer.deserialize_str(SmartVisitor)
}
}
impl Sample {
pub fn run(self) {
match self.lib {
Lib::Std => self.read_records::<String>(),
Lib::Smol => self.read_records::<smol_str::SmolStr>(),
Lib::Smart => self.read_records::<SmartWrap>(),
}
}
}
Let's try it!
$ cargo build && ./target/debug/small sample --lib smart 2>! events.ldjson && ./target/debug/small report events.ldjson
Compiling small v0.1.0 (/home/amos/ftl/small)
Finished dev [unoptimized + debuginfo] target(s) in 0.95s
Read 1000 records
found 35 events
⡁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈⡏⠉⡏ ⠁⠈ ⡁ 73813.0
⠄ ⡇ ⡇ ⠄
⠂ ⡇ ⡇ ⠂
⡁ ⡇ ⡇ ⡁
⠄ ⡇ ⡇ ⠄
⠂ ⡇ ⡇ ⠂
⡁ ⡇ ⣇⣀⣀⣀ ⡁
⠄ ⡇ ⠄
⠂ ⡇ ⠂
⡁ ⡇ ⡁
⠄ ⡏⢹ ⡇ ⠄
⠂ ⡇⢸ ⡇ ⠂
⡁ ⡇⢸ ⡇ ⡁
⠄ ⡇⠘⠒⠒⠒⠃ ⠄
⠂ ⡇ ⠂
⡁ ⢸⠉⢹ ⡇ ⡁
⠄ ⢸ ⢸⣀⡇ ⠄
⠂ ⡤⠤⡄⢸ ⠂
⡁ ⢀⣀⣀ ⡇ ⠓⠚ ⡁
⠄ ⢀⣀⣀ ⣀⣀⣀⣰⠒⠲⠤⠤⠼ ⠘⠒⠃ ⠄
⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉⠉ ⠉⠉⠁⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁⠈ ⠁ 1.0
0.0 35.0
total events | 35
peak bytes | 73.8 KB
----------------------------
alloc events | 19
alloc bytes | 98.4 KB
----------------------------
freed events | 16
freed bytes | 49.2 KB
This is the best performance we've seen so far. We're down to 19 allocation events, and peak memory usage of 73.8 KB.
Let's summarize
Here's a quick comparison of the feature sets:
| Type | Serde | Max inline | Stream-friendly | Mutable | unsafe | Clone |
|---|---|---|---|---|---|---|
| &'a str | Built-in | (borrowed) | no | no | - | O(1) |
| String | Built-in | 0 | yes | yes | - | O(n) |
| SmolStr | Feature | 22 | yes | no | no | O(1) |
| SmartString | In progress | 23 | yes | yes | yes | O(n) |
A PR for serde support in smartstring has been merged.
Let's now compare the memory characterestics for our sample workload:
| Type | Peak memory usage | Total memory events |
|---|---|---|
| String | 82.7 KB | 2033 |
| SmolStr | 73.9 KB | 42 |
| SmartString | 73.8 KB | 35 |
Finally, let's look at three microbenchmarks, which relevance I absolutely cannot guarantee. Microbenchmarks lie all the time.
In particular, those graphs completely ignore the things we've just learned about the number of allocation operations, they completely ignore the effects of cache locality - they're just that - microbenchmarks.
Even then, we can still validate some instincts by looking at them.
Note that all these graphs use a logarithmic scale.
They were run on an Intel(R) Xeon(R) CPU E5-1650 v2 @ 3.50GHz.
The legend (top right) shows:
stringforstd::string::Stringsmolforsmol_str::SmolStrsmartforsmartstring::SmartString<LazyCompact>
No mutations are being benchmarked, so testing Compact probably wouldn't make sense.
The first one builds a "string" from a &str:

This is a O(n) operation, as none of the types have any choice but to copy the entire
contents to their own storage.
For long (>22 bytes) strings, we can see smol has a slight constant overhead over
SmartString and String. That's not surprising, as smol uses
Arc<str> for those - which also means it's Send and Sync.
The second benchmark simply clones a "string":

This is where smol_str shines.
For short strings, SmartString wins. For longer strings, SmolStr::clone is O(1), since
it's just incrementing the reference count of an Arc.
The final benchmark converts a "string" back into the String type:

This one is particularly interesting to me - it looks a bit noisy, as if there were too many outliers. And there were, probably! But that's not the whole story.
For short strings, both smartstring and smol_str need to actually build a
String from scratch: which means allocating the String struct itself, and
its storage on the heap. For longer strings, it looks like smol is doing twice the work!
Is it allocating storage and copying twice? I'm not sure.
Go look for yourself and report back!
What don't those benchmarks show, though?
We've used both crates to deserialize JSON records, but that's not what
either says to use them for. smol_str is used in
rowan, itself used by rust-analyzer -
its README says its primary use case is "good enough default storage for
tokens of typical programming languages". We haven't experimented with its
whitespace-specific features at all.
As for smartstring, it's recommended for "a key type for a B-tree" (such as
BTreeMap),
because inline strings greatly improve cache
locality. This is something
none of our benchmarks even touched.
This concludes our comparison of String, SmolStr, and SmartString -
even though there would be a lot more to say about them both.
Until next time, take care!
If you liked what you saw, please support my work!

