

AI is taking on an increasingly important role in many Microsoft products, such as Bing and Office 365. In some cases, it’s being used to power outward-facing features like semantic search in Microsoft Word or intelligent answers in Bing, and deep neural networks (DNNs) are one key to powering these features. One aspect of DNNs is inference—once these networks are trained, they use inference to make judgments about unknown information based on prior learning.
In Bing, for example, DNN inference enables multiple search scenarios including feature extraction, captioning, question answering, and ranking, which are all important tasks for customers to get accurate, fast responses to their search queries. These scenarios in Bing have stringent latency requirements and need to happen at an extremely large scale. As these inference scenarios and associated models grow in complexity and scale, the resources needed for inference are growing too—between 3–5 times per year (see Figure 1).
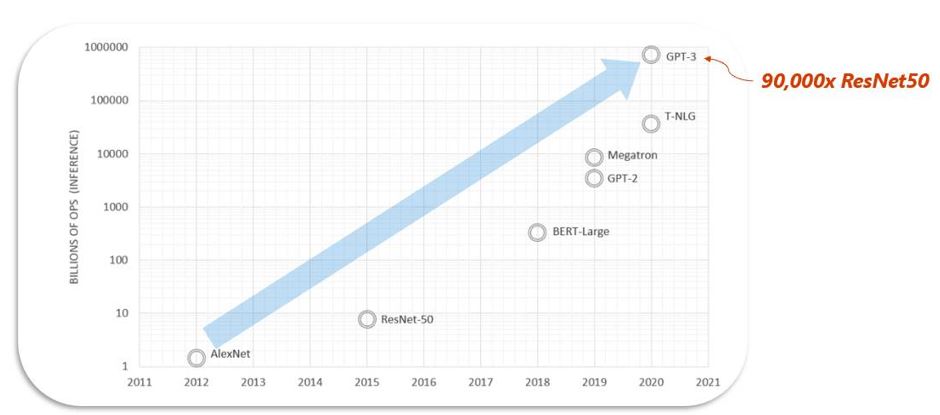
This growth trend line underscores the importance of minimizing the cost of inference for Microsoft. Data types—that is, the formats used to represent data—are a key factor in the cost of storage, access, and processing of the large quantities of data involved in deep learning models. In this blog post, we present a brief introduction to MSFP, a new class of data types optimized for efficient DNN inferencing, and how it is used in Project Brainwave to provide low-cost inference at production scale. Project Brainwave and its technology play a critical role in powering the infrastructure for AI at Scale, the Microsoft initiative to incorporate next-generation AI into its products and AI platforms. Our latest work is detailed in a paper accepted at the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), titled “Pushing the Limits of Narrow Precision Inferencing at Cloud Scale with Microsoft Floating Point.”
-
 Event
Microsoft at NeurIPS 2020
Event
Microsoft at NeurIPS 2020
Check out Microsoft's presence at NeurIPS 2020, including links to all of our NeurIPS publications, the Microsoft session schedule, and links to open career opportunities.
Microsoft Floating Point provides higher accuracy with low cost
Choosing how to represent numeric values in a computing platform is a trade-off between accuracy and cost. Using fewer bits per value, or moving from a floating-point to a fixed-point or integer format, decreases storage and computation costs but typically results in lower accuracy, that is, lower quality of results. MSFP is a new class of data types that deliver a fundamental shift in this trade-off, providing higher accuracy using fewer bits per value than traditional floating-point or integer formats. In particular, MSFP enables dot product operations—the core of the matrix-matrix and matrix-vector multiplication operators critical to DNN inference—to be performed nearly as efficiently as with integer data types, but with accuracy comparable to floating point.
Floating-point formats capture a large dynamic range by using an exponent field to scale the significance of the value captured by the mantissa bits. Unfortunately, this exponent field requires additional bits to be stored with each value, and greatly complicates the process of adding or multiplying values. Eliminating the exponent, resulting in a fixed-point or integer representation, reduces computation and storage costs but at a potentially significant reduction in accuracy due to the loss of dynamic range. MSFP delivers the dynamic range of floating point at close to the cost of integer formats by associating a single exponent with a group, or “bounding box”, of mantissa values. MSFP is a class of data types parameterized by the number of mantissa and exponent bits and the bounding box size (see Figure 2). In this post, we’ll focus on two versions of the data type, MSFP12 and MSFP16, which represent two points in the cost/performance trade-off spectrum for MSFP types.
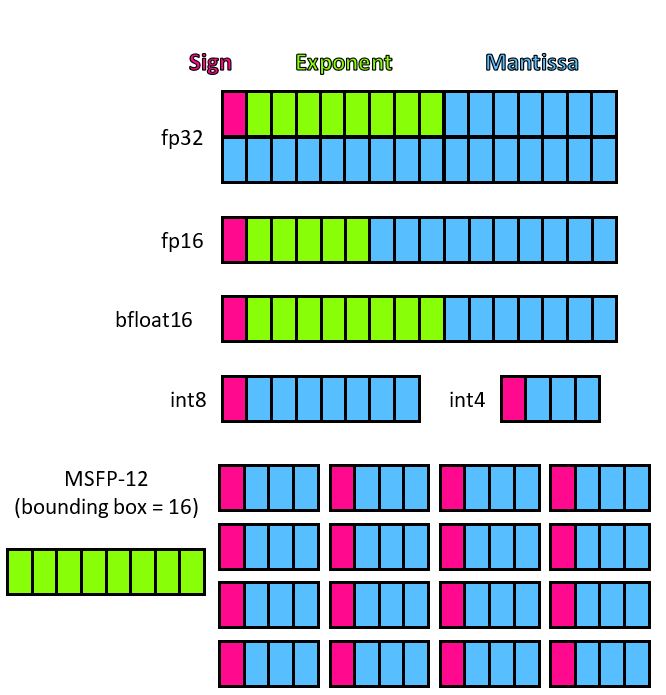
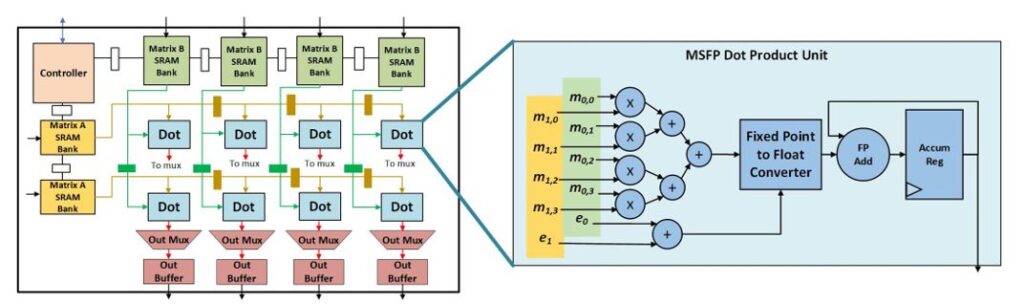
Through the coevolution of hardware design and algorithms, MSFP16 achieves 3x lower cost compared to Bfloat16, and MSFP12 achieves 4x lower cost compared to industry standard INT8 while delivering a comparable or better accuracy. Figure 3 shows the high-level overview of a systolic tensor core architecture containing multiple MSFP dot product units. Each dot product unit has a significantly lower circuit footprint compared to conventional float due to the shared exponent. We refer to the granularity at which the exponent is being shared between tensor elements as “bounding box size.” The math per bounding box is mostly performed in fixed-point format and the cost of dynamic scaling is amortized over the number of elements in each bounding box. To hide this complexity from software, the bounding box exponents are computed and updated in real time in hardware.
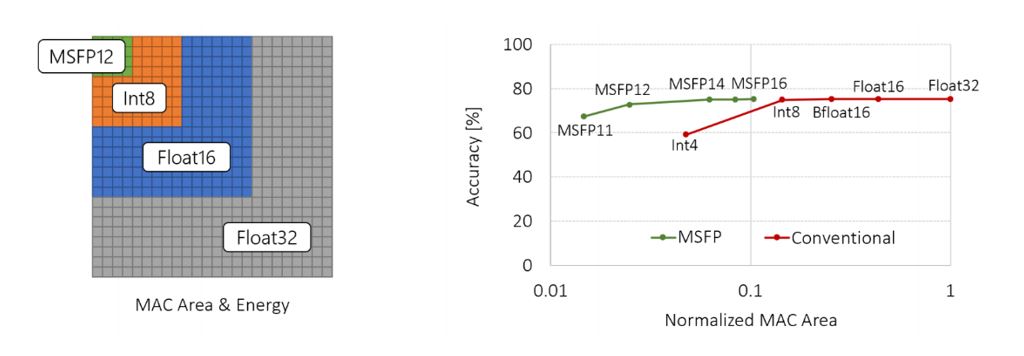
Variants of MSFP together form a new Pareto frontier for computational performance/mm2 compared to a collection of competitive data types on commodity hardware. Figure 4 shows the accuracy–area trade-off of using different data types for serving ResNet50 (ImageNet). MSFP outperforms existing data types in terms of area and energy cost while the model is held to a fixed accuracy.
MSFP is integrated within a mature large-scale production pipeline and has been used to ship various models empowering major online scenarios such as web search, question-answering, and image classification. We further corroborated the efficacy of MSFP data type for inferencing various open-source benchmarks from different classes of deep learning models including CNNs, RNNs, and Transformers. Please refer to Table 1 below and the paper for more details.
| Models | Float32 | MSFP16 | MSFP15 | MSFP14 | MSFP13 | MSFP12 |
|---|---|---|---|---|---|---|
| Resnet-50 | 1.000 (75.26) | 1.000 | 0.999 | 0.994 | 0.989 | 0.967 |
| Resnet-101 | 1.000 (76.21) | 1.000 | 1.000 | 0.998 | 0.991 | 0.964 |
| Resnet-152 | 1.000 (76.58) | 1.000 | 1.001 | 0.997 | 0.991 | 0.968 |
| Inception-v3 | 1.000 (77.98) | 1.000 | 1.005 | 1.001 | 0.990 | 0.943 |
| Inception-v4 | 1.000 (80.18) | 1.000 | 1.001 | 1.000 | 0.993 | 0.963 |
| MobileNet-V1 | 1.000 (70.90) | 0.998 | 0.997 | 0.990 | 0.965 | 0.863 |
| VGG16 | 1.000 (70.93) | 1.000 | 1.004 | 1.005 | 1.003 | 1.002 |
| VGG19 | 1.000 (71.02) | 1.000 | 1.002 | 1.001 | 1.002 | 1.000 |
| EfficientNet-S | 1.000 (77.61) | 1.000 | 0.998 | 0.992 | 0.979 | 0.949 |
| EfficientNet-M | 1.000 (78.98) | 1.000 | 0.998 | 0.993 | 0.980 | 0.950 |
| EfficientNet-L | 1.000 (80.47) | 1.000 | 0.999 | 0.993 | 0.974 | 0.945 |
| RNN-DR | 1.000 (76.10) | 1.000 | 1.008 | 1.003 | 1.009 | 1.000 |
| RNN-DS | 1.000 (73.10) | 1.000 | 1.012 | 1.005 | 1.022 | 0.992 |
| BERT-MRPC | 1.000 (88.39) | 1.000 | 1.005 | 1.002 | 1.008 | 1.018 |
| BERT-SQuAD1.1 | 1.000 (88.45) | 1.000 | 0.998 | 0.998 | 0.997 | 0.990 |
| BERT-SQuADv2 | 1.000 (77.23) | 1.000 | 0.999 | 0.999 | 0.993 | 0.989 |
| Memory density | 1.0x | 3.8x | 4.3x | 4.9x | 5.8x | 7.1x |
| Arithmetic density | 1.0x | 8.8x | 10.8x | 13.9x | 18.3x | 31.9x |
Project Brainwave takes MSFP to production
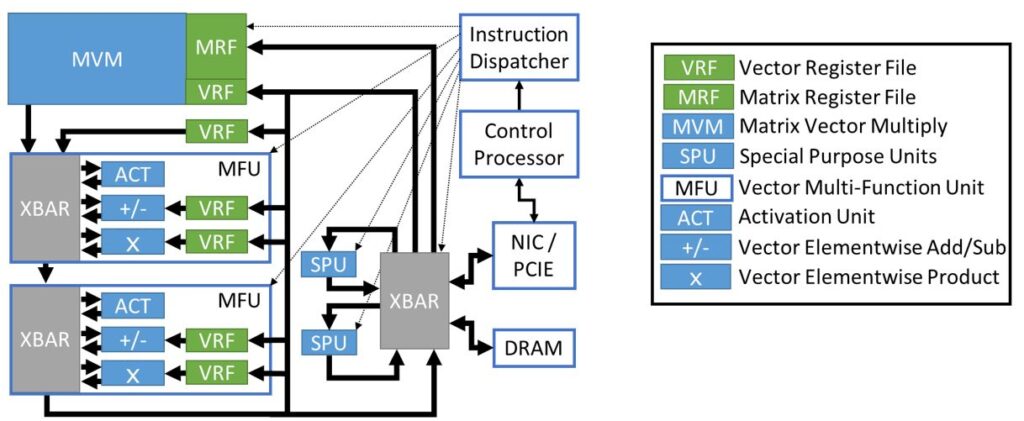
Microsoft leverages the benefits of MSFP via Project Brainwave, an internally developed system for real-time production-scale DNN inference in the cloud. Project Brainwave is used heavily in Bing and for our Office 365 workloads. Figure 5 shows a high-level view of the Project Brainwave Neural Processing Unit (NPU) architecture. The most critical part of the NPU is the matrix-vector multiplier (MVM) shown in the upper left. The MVM unit and associated matrix register file (MRF) and vector register file (VRF) are designed from the ground up to exploit the MSFP format.
Project Brainwave builds on the field-programmable gate arrays (FPGAs) deployed in Microsoft data centers as part of Project Catapult. The fine-grain bit-level configurability of FPGAs allows us to harvest the increased computational, storage, and bandwidth efficiencies of each incremental reduction in the bit width of the values on which we operate, which is critical for taking advantage of MSFP. FPGA flexibility has also enabled us to experiment and push the boundaries of low-precision computation for DNN inference. We were able to deploy MSFP to production at low risk because the parameters of our MSFP implementation can be adjusted simply by re-synthesizing our FPGA configuration.
Hardening MSFP in custom silicon
Now that MSFP has been proven in large-scale production systems, a natural next step is to consider hardening the performance-critical logic into custom silicon. Working together with our partners in the Intel Programmable Solutions Group (PSG), we’ve delivered significant improvement in area and energy efficiency through silicon hardening—resulting in the industry’s first AI-accelerated FPGA using MSFP tensor cores. The Intel Stratix 10 NX device represents the first generation of its kind bringing together Microsoft algorithms embedded into hardened silicon while continuing to harness the advantages of flexible reconfigurable hardware.
In the Stratix 10 NX device, over 4,000 custom digital signal processing (DSP) blocks deliver over 250 peak teraflops of MSFP. These hardened units are uniquely architected to blend seamlessly with reconfigurable logic, supporting flexible dataflows that can be finetuned for target applications—for example, the ability to scale up and down tensor cores while supporting varying degrees of sparsity. Given the rapid change in state-of-the-art inference algorithms, the NX enables Microsoft to continue evolving its hardware platform to handle and accelerate best-of-breed AI algorithms (without the drawbacks of multi-year silicon turnarounds).
Project Brainwave gains momentum for next-gen technologies
MSFP represents a major turning point in the journey that started in 2016 to deliver large-scale inferencing capabilities for Microsoft. Our understanding and research of low-precision arithmetic has advanced by leaps and bounds, with our confidence strengthened by the success of dozens of state-of-the-art AI models that have been deployed for critical scenarios in Bing and Office 365 using MSFP.
Project Brainwave, a platform leveraging reconfigurable logic, has provided the critical and flexible hardware platform to evolve algorithms with confidence. As research in low precision and sparsity continues to advance, we expect Project Brainwave—turbocharged by hardened MSFP—will continue to play a pivotal role in enabling us to deliver the next wave of advantages through algorithm codesign in hardware. We’re extremely excited for what’s coming next.
Acknowledgments
Microsoft Floating Point, and this work specifically, would not be possible without the broad team of engineers and researchers involved. We’d particularly like to thank Daniel Lo and Ritchie Zhao for their critical contributions, as well as Ming Liu, Jeremy Fowers, Kalin Ovtcharov, Anya Vinogradsky, Sarah Massengill, Lita Yang, Ray Bittner, Alessandro Forin, Haishan Zhu, Taesik Na, Prerak Patel, Shuai Che, Ahmad El Husseini, Lok Chand Koppaka, Xia Song, Subhojit Som, and Kaustav Das. We also thank Maximilian Golub, Rasoul Shafipour, and Greg Yang for their feedback on the draft of the paper. We thank Raja Venugopal for his support of this work.

