

Attacked Over Tor
Friday, 5 May 2017
For over 6 months, I have been running a Tor Hidden Service that provides a front-end to the Internet Archive (archive.org). The hidden service is at: http://archivecrfip2lpi.onion/ (This link only works if you are on Tor.)
From running my other services, I think I know how to make an optimized web server. FotoForensics, for example, is handling some pretty impressive network loads. In fact, my two main sites have only gone down a few times. There was the Body by Victoria blog entry, Boston Marathon bombing, World Press Photo, and the explicit denial of service attack. Beyond outages, I've had various attacks from dumb bots and big search engines. (I still haven't forgiven Google for abusing FotoForensics and submitting random words into search forms. Half of my current anti-attack code came about after attacks from Google.)
With each of these service outages and issues, I learned, made changes, and improved the system's performance. None of my systems are completely bullet proof -- another large denial-of-service could knock these public sites offline. (Please don't do that.) But I'm no longer worried about having my services listed on the front-page of Reddit, Slashdot, or other major social networks.
However, running this hidden service has been a learning experience. The problems that I'm experiencing with my Tor Hidden Service are similar but different from non-Tor services. They have the same basic causes -- bots and denial-of-service attacks -- but the Tor architecture introduces a serious problem. This problem leads to choke point on the hidden service server. Bad bots and attackers can create a bottleneck, resulting in a denial of service. Without rewriting the tor daemon or spawning dozens of parallel servers, there are few mitigation options.
I quickly wrote a couple of rules to detect these poorly behaved mirror-bots and block their access. This stopped most of the abuse. A few more rules stopped the vulnerability scanners and blind attackers who tried SQL-injection, overflows, and other malicious actions. Stopping these abuses sped up the response times for real users who wanted to access the Internet Archive over Tor.
As far as how to stop them... I had discussed this with a couple of people at the Internet Archive. At their recommendation, I began to return HTTP 403 "Forbidden" responses. If your bot sees this kind of response, it should stop. And if you make changes so that your bot avoids the 403 response, then you are attacking the site. Please don't attack my sites.
However, there's a few bots that have continued to attempt to mirror all of the Internet Archive through my little service. They ignore robots.txt, ignore HTTP 403 messages, continue to violate my terms of service. They have given me no other option but to use more active defenses.
My first deterrence was very simple. All five bots accept gzip encoding. So, I sent them zip-bombs. A gzip data stream maxes out at about 1032:1 compression. I can create a file that is 100K, but that decodes into 1 gigabyte. A 200K file on the wire expands into 2 gigabytes on the recipient's end.
Albert was first. He downloaded three of the 100K compressed zip bombs (that expanded into 1 gigabyte each) and stopped cold. This tells me that he unpacked them in memory, ran out of memory, and then crashed. It also means that he had about 2 gigs of RAM. So far (it's been a week), he hasn't been back.
Bobby and Chuck were almost as fast. Bobby downloaded 8 of the 1 gig zip bombs and then vanished. Chuck could handle the 1 gig zip bombs, but couldn't handle a dozen of the two-gig bombs.
With Albert, Bobby, and Chuck out of the way, I began to focus on Dennis and Eddie.
(As an aside: Why do I refer to misbehaving bots as guys? I may not know the gender of the person(s) running these bots, but they are clearly being dicks.)
Dennis has a built-in one-second pause. If I respond as fast as possible, he would visit once a second. If I pause 2 seconds before responding, then he visits every 3 seconds. And whoever is running Dennis runs multiple instances at the same time.
The problem with Dennis isn't that he's sucking up server resources. The problem is that he's trying to mirror the entire Internet Archive, and the Internet Archive has some really big files. This results in a resource issue related to my external bandwidth. Moreover, he has never accessed my robots.txt and ignores 403 errors.
As an active deterrence, I tried to fill up his hard drive with zip bombs. However, he appears to store the compressed data (or he has more than a few terabytes of free disk space). When that failed, I went after his queue.
The parser that Dennis uses looks for URLs and adds them to a queue. I won't give exact details here, but I found out how to crash his parser. Crashing his parser was all it took to make him stop. He did restart a few times, but gave up after repeated crashes. Oddly, when he eventually came back, he didn't start re-parsing his queue. Instead, he saw a "403 Forbidden" (with no URLs to parse) and stopped.
My interpretation here is that I didn't just crash his parser. I also caused Dennis to flush his queue. (I wouldn't be surprised if the human user saw the crashes and manually flushed the queue before restarting.)
This defense stopped Dennis for a few days. But he came back this morning, and he appears to have fixed his parsing problem. He's still ignoring 403 errors, still ignores robots.txt, but since he isn't downloading anything from the Internet Archive, he has been downgraded from an active threat to a nuisance. (And my counter-defense seems to take him down periodically.)
So what is he doing? He's exploiting a vulnerability in the Tor daemon. The same Tor process that you use for relaying onto Tor is used on my server for relaying to my hidden service. It's the exact same code. Except with the hidden service, the Tor daemon does one more thing... it connects to my local web server. This is what the Tor code does: it forwards traffic from the Tor network to my own service.
In this case, Eddie establishes a Tor connection to my service. (That's one network connection from Tor to me.) Then he sends a bunch of rapid open/close connections from the Tor client to my web server. If I had not optimized the connection timeouts on my local server, then he would rapidly consume all network ports. This is a resource exhaustion attack. And while many web servers are optimized to prevents this type of attack on the external network connection, few are configured to prevent this over the loopback adapter.
If I delay my responses to Eddie by more than 2 seconds, then Eddie can consume enough ports that Tor begins to fail to allocate new ports. This prevents users on Tor from accessing my hidden service. If I had not previously altered my network timeouts, then he would have consumed all available ports almost immediately. Fortunately, Eddie hasn't been able to kill my hidden service, but he has been able to slow it down.
I've spent the last few days optimizing both the internal and external connection and garbage collection settings. I've also been working to slow down Eddie. He had been hitting me at more than 20 connections per second. I've currently got him reduced to 4-8 requests per second (one second per parallel Eddie process). Fortunately, non-Eddie users are getting a fast response time.
I've been working with a couple of people to track down Eddie. I'm not going to detail all of the magic that we had to conjure up in order to track him. But I'm pretty confident in the current findings. Eddie consists of 3-4 high-speed servers, all located in either Germany or France.
While searching for him, Joe Klein and I noticed that there were an oddly high number of "Unnamed" high-speed Tor nodes in France and Germany. Of the current 604 unnamed Tor nodes (as seen on 2017-05-04), 159 are in the United States, 105 are in Germany, and 64 are in France. But when sorted by bandwidth, 15 of the top 30 are from France. Germany comes in second, with 7.
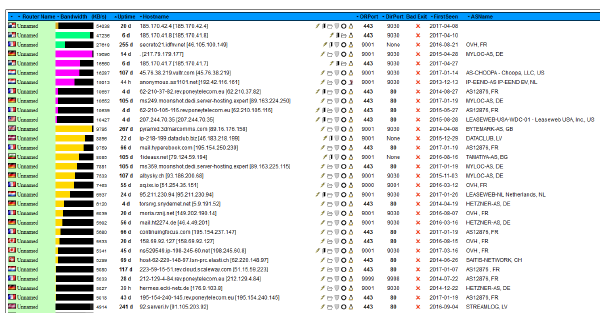
Of these fastest nodes, three of them are very interesting. They are [185.170.41.8], [185.170.41.7], and [185.170.42.4]. (In the above graph, the suspicious nodes are the 1st, 2nd, and 5th lines.) Now, I want to be clear: I am not convinced that these servers are Eddie. While looking for Eddie, we found these Tor servers. And these Tor servers, by themselves, seem very odd. Among the odd things:
The registration information bounces between multiple countries and never actually identifies the source. And they were all registered recently. If you talk to any cybersleuths about identity theft, spam, online fraud, scams, and fronts, they will tell you that misleading registration and bouncing between countries is a big red flag. This is some type of front. And it's deep enough to either be organized crime or a nation-state.
Perhaps the owner of the bot checked the logs. 11pm in Colorado is 7am in France and Germany, and 8am in Moscow.
Then again, a lot of denial-of-service attacks are programmed to start at a specific time and end at a specific time. Running for exactly 24 hours, exactly 48 hours, or exactly 1 week are common. I mentioned that the attack started on April 20th. It stopped almost exactly 2 weeks later.
And then there's that correlation with three suspicious Tor nodes. Shortly after the attack stopped, the volume of traffic through those nodes dropped dramatically.

In this graph, the suspicious Tor nodes are the first three lines. (I seriously doubt that my hidden service was the only one being attacked. I bet all of the attacks suddenly stopped.)
So why would they be attacking my little Tor hidden service? Or more specifically, who would not want people to access the Internet Archive over Tor? This is where we dive into conspiracies. For example, the first French election was held on 2017-04-23 (right after the attack started), and the run-off will happen on 2017-05-07 (which is days after the volume of the attack increased). The attack stopped less than a day after President Obama endorsed French candidate Emmanuel Macron. Assuming that this attack was related to the French election, it could take a day for Le Pen supporters, or a nation-state trying to influence the election, to change tactics. (Like Donald Trump, Le Pen wants to restrict Internet access. Both Tor and the Internet Archive are threats because they promote an open Internet.)
If I could easily tear down the entire tunnel from the remote client to my hidden service, then the delay to rebuild the tunnel would mitigate the resource exhaustion attack. I'm not asking for a way for someone to arbitrarily close any connection; I want a way for the hidden service to control which connections to it are permitted. For example, if I see hostile activity from 127.0.0.1:12345, then I want to close the entire Tor connection associated with this port. This won't prevent the attacker from coming back over a different port, but it does delay the attacker by forcing him to renegotiate the entire tunnel.
Update: I have a follow-up in The Continuing Tor Attack
From running my other services, I think I know how to make an optimized web server. FotoForensics, for example, is handling some pretty impressive network loads. In fact, my two main sites have only gone down a few times. There was the Body by Victoria blog entry, Boston Marathon bombing, World Press Photo, and the explicit denial of service attack. Beyond outages, I've had various attacks from dumb bots and big search engines. (I still haven't forgiven Google for abusing FotoForensics and submitting random words into search forms. Half of my current anti-attack code came about after attacks from Google.)
With each of these service outages and issues, I learned, made changes, and improved the system's performance. None of my systems are completely bullet proof -- another large denial-of-service could knock these public sites offline. (Please don't do that.) But I'm no longer worried about having my services listed on the front-page of Reddit, Slashdot, or other major social networks.
However, running this hidden service has been a learning experience. The problems that I'm experiencing with my Tor Hidden Service are similar but different from non-Tor services. They have the same basic causes -- bots and denial-of-service attacks -- but the Tor architecture introduces a serious problem. This problem leads to choke point on the hidden service server. Bad bots and attackers can create a bottleneck, resulting in a denial of service. Without rewriting the tor daemon or spawning dozens of parallel servers, there are few mitigation options.
On the attack
The first attacks against my Internet Archive hidden service began hours after the public announcement. A slew of bots all came in, trying to index the entire Internet Archive through my little hidden service. This is just insane -- the Internet Archive is massive, and Tor is slow. There is no way that it can pass all of the data. And it isn't like they were doing HTTP 'HEAD' requests -- no, they were doing 'GET' requests.I quickly wrote a couple of rules to detect these poorly behaved mirror-bots and block their access. This stopped most of the abuse. A few more rules stopped the vulnerability scanners and blind attackers who tried SQL-injection, overflows, and other malicious actions. Stopping these abuses sped up the response times for real users who wanted to access the Internet Archive over Tor.
As far as how to stop them... I had discussed this with a couple of people at the Internet Archive. At their recommendation, I began to return HTTP 403 "Forbidden" responses. If your bot sees this kind of response, it should stop. And if you make changes so that your bot avoids the 403 response, then you are attacking the site. Please don't attack my sites.
However, there's a few bots that have continued to attempt to mirror all of the Internet Archive through my little service. They ignore robots.txt, ignore HTTP 403 messages, continue to violate my terms of service. They have given me no other option but to use more active defenses.
On the defense
Today, only five bots are really appearing to be problems. I've named them after letters of the alphabet: Albert, Bobby, Chuck, Dennis, and Eddie. Of the 5 bots, Dennis and Eddie are very aggressive. But it wasn't until Eddie appeared (on April 20th) that I had to make more active defenses. (This is when I realized that Eddie was more than a mirror bot.)My first deterrence was very simple. All five bots accept gzip encoding. So, I sent them zip-bombs. A gzip data stream maxes out at about 1032:1 compression. I can create a file that is 100K, but that decodes into 1 gigabyte. A 200K file on the wire expands into 2 gigabytes on the recipient's end.
Albert was first. He downloaded three of the 100K compressed zip bombs (that expanded into 1 gigabyte each) and stopped cold. This tells me that he unpacked them in memory, ran out of memory, and then crashed. It also means that he had about 2 gigs of RAM. So far (it's been a week), he hasn't been back.
Bobby and Chuck were almost as fast. Bobby downloaded 8 of the 1 gig zip bombs and then vanished. Chuck could handle the 1 gig zip bombs, but couldn't handle a dozen of the two-gig bombs.
With Albert, Bobby, and Chuck out of the way, I began to focus on Dennis and Eddie.
(As an aside: Why do I refer to misbehaving bots as guys? I may not know the gender of the person(s) running these bots, but they are clearly being dicks.)
Dennis
With Dennis, I began to feed him different types of results. These allowed me to profile the system. Based on how it reacted, I could tell that Dennis was a single-threaded streaming bot. It downloaded content, saved it to a file, and then streamed the file into a parser.Dennis has a built-in one-second pause. If I respond as fast as possible, he would visit once a second. If I pause 2 seconds before responding, then he visits every 3 seconds. And whoever is running Dennis runs multiple instances at the same time.
The problem with Dennis isn't that he's sucking up server resources. The problem is that he's trying to mirror the entire Internet Archive, and the Internet Archive has some really big files. This results in a resource issue related to my external bandwidth. Moreover, he has never accessed my robots.txt and ignores 403 errors.
As an active deterrence, I tried to fill up his hard drive with zip bombs. However, he appears to store the compressed data (or he has more than a few terabytes of free disk space). When that failed, I went after his queue.
The parser that Dennis uses looks for URLs and adds them to a queue. I won't give exact details here, but I found out how to crash his parser. Crashing his parser was all it took to make him stop. He did restart a few times, but gave up after repeated crashes. Oddly, when he eventually came back, he didn't start re-parsing his queue. Instead, he saw a "403 Forbidden" (with no URLs to parse) and stopped.
My interpretation here is that I didn't just crash his parser. I also caused Dennis to flush his queue. (I wouldn't be surprised if the human user saw the crashes and manually flushed the queue before restarting.)
This defense stopped Dennis for a few days. But he came back this morning, and he appears to have fixed his parsing problem. He's still ignoring 403 errors, still ignores robots.txt, but since he isn't downloading anything from the Internet Archive, he has been downgraded from an active threat to a nuisance. (And my counter-defense seems to take him down periodically.)
Eddie
Eddie is the newest and most aggressive of the misbehaved bots. I haven't been able to stop him, and he has the ability to impact regular users who want to access the hidden service. What I know about Eddie:- He is a very rapid bot. If I respond as fast as possible, then he can make 20-30 or more requests per second. Eddie accounts for over 70% of the requests to my hidden service over the last week.
- He ignores all return codes. I've been sending him "403 Forbidden" responses for days, and he just continues.
- He has a 10 second timeout. If I don't respond in 10 seconds, or if my response does not finish transmitting data within 10 seconds, then he disconnects and tries a different URL. Among other things, it means that I cannot send him the 10 gig zip bomb. Tor is a slow network -- after sending 700kb-800kb of the 1000kb data, he disconnects due to his timeout. It also means that he doesn't care about the response -- he only cares about making requests.
- Normally I don't track requests. (My web logs don't even list the requested URL.) However, I can readily identify Eddie based on a half-dozen unique signatures. So for Eddie, I began logging his attacks. He requests some URLs that were never sent to him and he ignores all data that I send him. If I send him custom URLs for tracking, he never accesses the URLs. Here's a sample of the URLs that he requests:
He looks like he's doing search engine abuse -- submitting random searches and looking at the results. And he looks like he's going after a couple of responses. This collection of random queries and random results makes Eddie very different from a mirroring bot. Eddie isn't mirroring. He wants to look like he's trying to crawl the Internet Archive, but that's a cover-up for his real purpose. (I'll get to his real purpose in a moment.)GET /details/zx_ZZZ_UNK_Gol
GET /search.php?query=collection%3Aetree+AND+format%3Amp3+AND+creator%3A%22The+Visions%22
GET /details/911?chan=PSC&time=200109161810
GET /bookmarks.php?add_bookmark=1&identifier=RockyJordan&mediatype=audio&title=Rocky+Jordan
GET /details/911?chan=PSC&time=200109161820
GET /details/zx_Quondam_1989_Ocean_a2
GET /search.php?query=collection%3Aetree+AND+format%3Amp3+AND+creator%3A%22The+Vista+Stringband%22
GET /details/911?chan=PSC&time=200109161830
GET /search.php?query=collection%3Aetree+AND+format%3Amp3+AND+creator%3A%22The+Vital+Might%22
GET /details/zx_Sea_of_Zirun_1985_Gilsoft_International_a
GET /details/911?chan=PSC&time=200109161840
GET /search.php?query=subject%3A%22A+Man+Named+Jordan%22
GET /details/zx_Spectrasmash_Intro_1983_Romik_Software_16K
GET /search.php?query=collection%3Aetree+AND+format%3Amp3+AND+creator%3A%22The+Vivid+Tangerines%22
GET /details/911?chan=PSC&time=200109161850
GET /search.php?query=subject%3A%22A+Man+Called+Jordan%22
GET /details/911?chan=PSC&time=200109161900
GET /details/zx_ZZZ_UNK_Gyufa
GET /search.php?query=collection%3Aetree+AND+format%3Amp3+AND+creator%3A%22The+Void%22
GET /search.php?query=subject%3A%22Casablanca%22 - He cycles through connections faster than my hidden service cycles through connections. He connects, sends some GET requests, and then disconnects. Each of Eddie's processes repeats this a few times per minute.
- He has an extremely high bandwidth. I benchmarked my own Tor clients. He's faster than a Tor client going through the typical 3 Tor node chain. He's even faster than a 1-node Tor chain. I strongly suspect that Eddie is actually a high-speed Tor relay.
So what is he doing? He's exploiting a vulnerability in the Tor daemon. The same Tor process that you use for relaying onto Tor is used on my server for relaying to my hidden service. It's the exact same code. Except with the hidden service, the Tor daemon does one more thing... it connects to my local web server. This is what the Tor code does: it forwards traffic from the Tor network to my own service.
In this case, Eddie establishes a Tor connection to my service. (That's one network connection from Tor to me.) Then he sends a bunch of rapid open/close connections from the Tor client to my web server. If I had not optimized the connection timeouts on my local server, then he would rapidly consume all network ports. This is a resource exhaustion attack. And while many web servers are optimized to prevents this type of attack on the external network connection, few are configured to prevent this over the loopback adapter.
If I delay my responses to Eddie by more than 2 seconds, then Eddie can consume enough ports that Tor begins to fail to allocate new ports. This prevents users on Tor from accessing my hidden service. If I had not previously altered my network timeouts, then he would have consumed all available ports almost immediately. Fortunately, Eddie hasn't been able to kill my hidden service, but he has been able to slow it down.
I've spent the last few days optimizing both the internal and external connection and garbage collection settings. I've also been working to slow down Eddie. He had been hitting me at more than 20 connections per second. I've currently got him reduced to 4-8 requests per second (one second per parallel Eddie process). Fortunately, non-Eddie users are getting a fast response time.
Who is Eddie?
There's a saying in the computer security field: if you own the server, you own the user. The same holds true with Tor. I really do value anonymity and privacy. And the Tor Project has done a very good job making it hard to track systems. Having said that... it just means I have to work harder to find out who is attacking me. (And I have a very large toolbox of dirty tricks that I will use against attackers.)I've been working with a couple of people to track down Eddie. I'm not going to detail all of the magic that we had to conjure up in order to track him. But I'm pretty confident in the current findings. Eddie consists of 3-4 high-speed servers, all located in either Germany or France.
While searching for him, Joe Klein and I noticed that there were an oddly high number of "Unnamed" high-speed Tor nodes in France and Germany. Of the current 604 unnamed Tor nodes (as seen on 2017-05-04), 159 are in the United States, 105 are in Germany, and 64 are in France. But when sorted by bandwidth, 15 of the top 30 are from France. Germany comes in second, with 7.
Of these fastest nodes, three of them are very interesting. They are [185.170.41.8], [185.170.41.7], and [185.170.42.4]. (In the above graph, the suspicious nodes are the 1st, 2nd, and 5th lines.) Now, I want to be clear: I am not convinced that these servers are Eddie. While looking for Eddie, we found these Tor servers. And these Tor servers, by themselves, seem very odd. Among the odd things:
- The TorStatus page has no country associated with the ASN information. In fact, of the 604 unnamed Tor nodes, only 6 have no ASN information -- three are hosted at "cloudatcost.com" (a cloud hosting provider), the other three are these unidentified addresses.
- To find the ASN information, we had to look through other methods. According to MaxMind, they are part of AS395978. A six-digit ASN number means it was registered pretty recently. According to WHOIS, it was registered around 2017-03-12. Unfortunately, MaxMind labels them as part of an anonymous proxy network. Hurricane Electric says that AS395978 has only one peer: AS174 -- that's Cogent. Cogent mainly provides service in the United States and Europe.
- The "First seen" dates (as recorded by TorStatus) are 2017-04-08, 2017-04-10, and 2017-04-27. The attacks from Eddie began on 2017-04-20 -- shortly after they were registered. The attacks picked up speed on 2017-04-27, when the third server came online.
- The WHOIS information for each of the three suspicious Tor nodes claims to registered to Trump Tower in Panama. NOTE: Regardless of my feelings about Trump, I believe this registration information is fake and it isn't really related to him.
inetnum: 185.170.41.0 - 185.170.41.255
org: ORG-OA825-RIPE
netname: OKSERVERS
country: PA
admin-c: OL2665-RIPE
tech-c: OL2665-RIPE
status: ASSIGNED PA
mnt-by: CYBR-DMZ
created: 2017-01-31T19:51:49Z
last-modified: 2017-04-29T11:18:45Z
source: RIPE
organisation: ORG-OA825-RIPE
org-name: OKSERVERS
org-type: OTHER
address: TRUMP TOWER
abuse-c: ACRO1670-RIPE
mnt-ref: CYBR-DMZ
mnt-by: CYBR-DMZ
created: 2017-03-12T11:26:43Z
last-modified: 2017-03-12T11:26:43Z
source: RIPE # Filtered - While these IP addresses have likely-fake WHOIS registration information, they are registered to a service provider in New York city: OkServers. Except that OkServers says that their servers are located in Romania -- not Germany. So this may also be fake registration information.
- Because the registration appears fake and lacks contact information, I reached out to RIPE (the registration provider). They said that they are investigating. Meanwhile, they directed me to the address space owner: ORG-RNL23-RIPE. I don't know how RIPE found this (I saw ORG-RNL25-RIPE, not ORG-RNL23-RIPE), but if they say it's the owner, then I believe them. This registrant is named Reachable Network (Pty) LTD, they are based out of South Africa, and they serve Germany and England.
Oddly, in the last 24 hours, the command 'whois ORG-OA823-RIPE' has changed to identify OKSERVERSORG in the Netherlands. And their registration record now says it was created on 2017-03-08 -- a few days before the other registration records.
organisation: ORG-OA823-RIPE
org-name: OKSERVERSORG
org-type: OTHER
address: NL
abuse-c: ACRO1670-RIPE
mnt-ref: CYBR-DMZ
mnt-by: CYBR-DMZ
created: 2017-03-08T20:37:55Z
last-modified: 2017-03-08T20:37:55Z
source: RIPE # Filtered
The registration information bounces between multiple countries and never actually identifies the source. And they were all registered recently. If you talk to any cybersleuths about identity theft, spam, online fraud, scams, and fronts, they will tell you that misleading registration and bouncing between countries is a big red flag. This is some type of front. And it's deep enough to either be organized crime or a nation-state.
Where's Eddie now?
Late last night, Eddie abruptly stopped. Here's the last log entries:[04/May/2017:23:00:50 -0600] "" 403 31 "" "Eddie"As far as I can tell, there's nothing I was doing that would have caused him to stop. The time that he stopped is also interesting -- near the top of the hour. (Off by 50 seconds? That's probably clock drift.) Perhaps Eddie had actually been processing some of the junk I returned to him, hit a long-queued-up zip-bomb, and died. But I kind of doubt it. As I mentioned, Eddie was multiple processes on multiple servers. (I'm very confident about that). So my zip-bombs would have taken down one process at a time; there wouldn't be a sudden stop.
[04/May/2017:23:00:50 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:50 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:50 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:51 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:51 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:51 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:51 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:00:51 -0600] "" 403 31 "" "Eddie"
[04/May/2017:23:10:03 -0600] "" 403 31 "" "Eddie"
Perhaps the owner of the bot checked the logs. 11pm in Colorado is 7am in France and Germany, and 8am in Moscow.
Then again, a lot of denial-of-service attacks are programmed to start at a specific time and end at a specific time. Running for exactly 24 hours, exactly 48 hours, or exactly 1 week are common. I mentioned that the attack started on April 20th. It stopped almost exactly 2 weeks later.
And then there's that correlation with three suspicious Tor nodes. Shortly after the attack stopped, the volume of traffic through those nodes dropped dramatically.
In this graph, the suspicious Tor nodes are the first three lines. (I seriously doubt that my hidden service was the only one being attacked. I bet all of the attacks suddenly stopped.)
So why would they be attacking my little Tor hidden service? Or more specifically, who would not want people to access the Internet Archive over Tor? This is where we dive into conspiracies. For example, the first French election was held on 2017-04-23 (right after the attack started), and the run-off will happen on 2017-05-07 (which is days after the volume of the attack increased). The attack stopped less than a day after President Obama endorsed French candidate Emmanuel Macron. Assuming that this attack was related to the French election, it could take a day for Le Pen supporters, or a nation-state trying to influence the election, to change tactics. (Like Donald Trump, Le Pen wants to restrict Internet access. Both Tor and the Internet Archive are threats because they promote an open Internet.)
A better mitigation option
Finally, there's one thing that the Tor Project could do to really help mitigate this situation. Right now and as far as I can tell, there's no way for a hidden service to shutdown a single connection. Closing the connection from my web server to the tor daemon does not close the connection from the daemon to the remote client. And restarting the tor daemon impacts all connections, not just the hostile one.If I could easily tear down the entire tunnel from the remote client to my hidden service, then the delay to rebuild the tunnel would mitigate the resource exhaustion attack. I'm not asking for a way for someone to arbitrarily close any connection; I want a way for the hidden service to control which connections to it are permitted. For example, if I see hostile activity from 127.0.0.1:12345, then I want to close the entire Tor connection associated with this port. This won't prevent the attacker from coming back over a different port, but it does delay the attacker by forcing him to renegotiate the entire tunnel.
Update: I have a follow-up in The Continuing Tor Attack
Just kidding, great article as usual!
(Not)
Fun.
Just for you: The next blog entry I do on Tor, I'll be sure to spell it Tor, TOR, ToR, tOR, and every other variation I can find.
https://www.torproject.org/docs/faq.html.en#WhatIsTor
That's what I get for trusting the Internet. Google claimed one time zone for France and two for Germany. But you're right -- same time zone for both. (The two for Germany are with and without daylight savings time.)
I've corrected the blog entry.
Great question. This is actually detailed in the blog entry where I announced the service (and where I released the source code for the service).
Currently, my Internet Archive hidden service is not integrated into their infrastructure. The Internet Archive has approved this service, their Archive Lab have seen the code, and it will be moved from my hardware over to their hardware (leading to a huge speed improvement and much less network delay). NOTE: This is not an endorsement from the Internet Archive.
However, moving the service to one of their systems is not a high priority for their IT staff right now. No ETA for when it will be moved. (I talk to the folks at the Internet Archive often, and they are just as eager as I am.)
Regarding whether I can see plain text: My service runs like a proxy. In theory, my server is in a position to see all data unencrypted. And there's a few lines of code where it actively alters unencrypted HTML content and HTTP headers. This is how I make all links stay within the Tor tunnel. The HTML from archive.org has a lot of hard-coded "https://archive.org/" URLs that would leave the tunnel if I didn't rewrite them. You see this same type of alteration on the tor2web services -- but I'm not using their code.
The specific alterations that my proxy makes:
1. For text/html content: I change all .archive.org hostnames to .archive[blah].onion. This keeps them in the Tor tunnel.
2. For HTTP header: If there's a redirection (301, 302, etc.), I alter the new location so it stays within the Tor tunnel. I also change the "Server:" and cookie fields so it matches the correct server. (I don't care what cookies get passed, but I want to make sure they match the correct domain.)
3. Over Tor, I use HTTP because (1) I don't have a valid cert for the .onion domain, and (2) Tor already uses better encryption than SSL, so HTTPS provides no added protection. For the connection to archive.org, I use HTTPS and I verify the certificate. The data in and out of my server is always encrypted (either by Tor or by HTTPS, depending on the direction).
4. Beyond HTML and HTTP: I replace robots.txt so well-formed bots know that they should not mirror the site.
As far as privacy goes: Right now, it runs on the honor system. I am not manually intercepting content or spying on users. But this is one of the reasons why I really want it moved onto the Internet Archive's servers: removing me from the loop ensures that you don't have to trust me to protect your privacy.
Edit: for clarity.
Hmm.. https://www.eff.org/pages/tor-and-https
Unless you're military, government, or paid per attack, most services don't count the number of attacks that fail. They only count the number that succeed (or that get close enough to succeeding that they get your attention). If they need metrics regarding failed attacks, then the get them from their logs long after the failed attack.
At FotoForensics, I don't count the number of sql-injection attacks or blind wordpress attacks. I have defenses in place and they handle it. If someone gets too aggressive, the automated defenses alert me. My automated defenses even handle common attack escalation procedures. (He's being a jerk, return nothing. He's still being a jerk, so ban him. He's still being a jerk, so block him. He's been repeatedly blocked, so blacklist him. Etc.)
By the same means, I doubt that the Internet Archive or Google are doing real-time counting of the number of daily attacks that fail. And they are big enough and distributed enough that even large attacks may not be noticed. Remember: the bigger you are, the bigger the mosquito needs to be to get your attention.
In fact whenever I use them (archive.org not the hidden service) I always feel like it's pretty slow.
*: compared with Google.
Oh! Please don't get me wrong. I don't think any public internet service is as big as Google. (I may be wrong: Facebook and Akamai are probably be close.)
But all of them are much bigger than me. My Tor hidden service is running on one VM with 2 CPUs and limited RAM. (Then again, FotoForensics is only a little bigger, and it handles a huge amount of traffic.)
I also look at them compared to the Alexa top 1 million web sites. Google is #1. Archive.org is #272. FotoForensics is currently #128,858, and Hackerfactor.com is #402,740. This translates into users. I don't have anywhere near as many people visiting my sites as Google or the Internet Archive.
From all of what you write someone just crawled onion addresses in a pretty stupid way.
What if I sent a ping to your web site. One ping isn't a problem.
What if I sent a ping a second? That's probably annoying, but not an attack.
What if I sent a ton of rapid pings -- enough to degrade your network performance? I just want to know if your site is still up. But you will likely view it as an attack.
What if I tell a hundred computers to all send pings to you? To each of them, it's just a few pings. To you, it's a flood. (It's actually called a Ping Flood or a Smurf Attack.)
Now, let's view this as a web bot:
What if I did "GET /" against your web site? That's fine.
What if I send a web crawler to index your entire site? If you have a robots.txt that says not to do it, then (in the United States) it can be classified as Digital Trespassing -- a felony. But to you, it might be an annoyance.
What if I tell my bot to go as fast as possible and to use as many parallel threads on as many parallel systems as possible? And what if the result of this bot is a notable consumption of network and system resources -- possibly impacting other users? That's an attack.
These five misbehaved bots all are classified as attacks.
I've also seen this type of misbehaved bot attack RSS feeds. My RSS feed updates 1-2 times per week. There is no reason for someone's RSS bot to request my RSS feed every 3 seconds. Rapid requests increase both the server load and bandwidth resources. (If you do that and I notice it, then you get banned.)
In general, I follow a simple rule: Once is a fluke, twice is coincidence, three times is an attack that needs a response/solution.
When you make a connection to a hidden service, each client is also assigned a hidden service address ([really-long-key].b32.i2p). Using this, you can follow annoying users, and block them from connecting to your hidden service
Nowadays we have so many crucial political events within a time frame that IMO it is hard easy to correlate an attack to a particular one (eg. the mentioned 20th April is a infamous known here, but not only here in Germany as the birthday of the f*ing "Führer").
Excellent points. And you're right -- it could be any of the recent political events. Or it could even be an unrelated jerk.
This is a chilling account, and glad you published it. I hope that it shines a light on bad practices and bad actors.
We hope that the Internet Archive can help highlight how the Internet, Web, Tor, etc can all be better. This is exactly in this spirit.
Thank you, and Thank you from a very large world of users and open system lovers.
-brewster
Digital Librarian
Internet Archive
You might find this presentation also interesting on the topic of tracking C2C using this kind of trick:
https://files.sans.org/summit/CTI_Summit_2017/PDFs/Hunting-Cyber-Threat-Actors-with-TLS-Certificates-Mark-Parsons.pdf
mtr on the ip do give be3128.agr21.fra03.atlas.cogentco.com as the 2nd to last node. As Cogent use IATA code to identify the network gear location and since FRA is Frankfurt, I guess this is in Germany. Since there is only 2 hops after, I suspect that the server is in a DC there.
149.14.156.250, the last hop before the tor node, is running ssh and show that's a cisco (as seen by "nc 149.14.156.250 22").
So I also suspect that the servers are in the Cogent DC.
Running whois on the 149.x ip show this belong to noxhosting, also located in Frankfurt. Their website however do not list colocation of custom servers as a service, so that's rather weird that someone did manage to get a custom AS there (or at least, that's uncommon enough to not be mentioned on the website).
Others ranges (for example 149.14.156.240/29) do follow some patterns:
149.14.156.241 is te0-2-0-1.rcr21.b015749-1.fra03.atlas.cogentco.com. (I suspect te0 mean 10G ethernet)
149.14.156.242 is newroz.demarc.cogentco.com
the whois tell this range belong to newroz telecom.
Looking at the reverse dns of the whole range, I see that 149.14.156.249 is also named like others routers with boundaries on a /29. So I suspect it to be the 10G router assigned to that customer, connected to what is supposed to be a firewall on the 250.
There is a few "nox hosting" company around there. I found one located in Texas, according to their twitter account, and was started less than 6 months ago. In fact, the domain was registered at the same time as the network got assigned by Cogent, 16-12-2016. They have also almost no presence on the web, and their offer do look strange (there is error in the offers, like "secound", "triple-core").
There is also no mention of anything in Germany, only US datacenters. The company address list a PO Box in Houston, which is also slightly sketchy.
So I think you are on something with those servers. Someone did took a great care to hide themself for this.
We traced the three suspicious Tor nodes to in/near Frankfurt, Germany.
However, we cannot conclusively prove that those three nodes are where Eddie is located. Using different tracing methods, we narrowed Eddie down to servers that are either in Germany or in France. But not to the three odd Tor nodes.
If this were a court case, then the associations between Eddie and the three odd Tor nodes would be circumstantial evidence -- and probably not strong enough to get a warrant.
Second of all, fake whois records has long been a tactic used to confuse so-called cyber experts like you who don't understand how the internet really words.
Thirdly, your investigative techniques are as sound and well reasoned as Louise Mensch's. You truely are the Louise Mensch of forensic experts.
Fourth, you can infact kill a specific stream or circuit by using the Control Port. You find the offending stream by finding the correct sourceip/port from tor to your webserver, from there you find the circuit id associated with that stream, then you close that circuit. Closing the stream only drops one connection, closing the circuit forces them to rebuild a new rendezvous circuit to connect back.
https://stem.torproject.org/api/control.html#stem.control.Controller.get_streams
https://stem.torproject.org/api/response.html#stem.response.events.StreamEvent
https://stem.torproject.org/api/control.html#stem.control.Controller.close_circuit
I thoroughly enjoyed the post until it went from interesting fact-based observations and logs to this is certainly a nation state conspiracy land
What vested interest do Trump or Le Pen have in restricting Tor access? Reading this sentence was like finding a dog turd in the beautiful garden that is the rest of your blog post. The rest of your post was excellent, but that part stuck out as absolute bullshit. Please either back up claims like this or don't bother making them, they just weaken the rest of your writing.
If P_1,P_2,...,P_(n-1),P_n are a set of propositions where P_j is true for all 0<j<n, then the fact that P_n is false has no impact on the truth of the P_j for 0<j<n.
... where P_j is true for all 0,...,n-1, then the fact that P_n is false does not change that P_j is true for all 0,...,n-1.
Perhaps someone knew this was coming and was attempting to mitigate the hackers ability to distribute the files? I don't know why the hackers would be required to use archive.org, but it's certainly an interesting coincidence
Link to story about the hack: https://techcrunch.com/2017/05/05/french-presidential-frontrunner-macrons-emails-leaked-after-alleged-hack/
Thank you for pointing this out. As you know, automated security analyzers typically generate a large number of false positives and still require a human to evaluate the results. In this case, the grade of "F" doesn't apply. Among other things:
Content Security Policy: As mentioned at https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP, "CSP compatible browser will then only execute scripts loaded in source files received from those whitelisted domains." None of my sites load script source files from other domains. Thus, there is no threat.
The three "X-" headers are all non-standard. (The "X-" means "non-standard". See: https://tools.ietf.org/html/rfc6648) In this case:
X-Content-Type-Options: Tells browsers not to guess the mime type. I provide the mime types, so this isn't an issue for my content.
X-Frame-Options: Tells whether a web site can appear in a frame. FotoForensics checks for frames and breaks out of them. For HackerFactor.com, there are no login for users, so there's no risk of it appearing in a frame.
X-XSS-Protection: This header tells browsers to not load if they detect a XSS. Since my site does not provide the capability for users to upload their own JavaScript, there's no risk of a XSS attack. This header isn't needed.
They also deducted points because my site supports both HTTP and HTTPS, rather than redirecting HTTP to HTTPS. Until HTTP is no longer a standard, I will support HTTP. And since I don't provide users with logins at HackerFactor.com, there's no risk for users to visit my site using HTTP.
Finally, there's HSTS. That's an OPTIONAL header that says "don't use HTTP if you came to this domain over HTTPS". Again, hackerfactor.com doesn't provide user accounts, so there's no risk if I switch between HTTP and HTTPS. And I don't believe I switch between HTTP and HTTPS for the hackerfactor.com domain. (I use relative URLs, not absolute URLs.) There's a good description of HSTS at https://www.owasp.org/index.php/HTTP_Strict_Transport_Security_Cheat_Sheet
Thanks for keeping an eye out for me. But I think I'm in good shape right now.
There is nothing on this site that prohibits you from typing "https://www.hackerfactor.com/" and accessing this site with HTTPS over Tor.
Right now, I want to support both HTTP and HTTPS. My reason is that many users still use old browsers. If I force everyone to use HTTPS, then some of the old browsers will be unable to access this content because their old browsers will have no supported ciphers.
Content Security Policy is intended to prevent XSS-flaws or other injection flaws frmo allowing an attacker to inject their own script into your page. If this comment box happened to not escape html and I typed <script src="https://evil.tld/evil.js"></script>, it still wouldn't execute if you enabled CSP.
Regarding X-Content-Type-Options, IE is known for ignoring the mime type you send if it thinks it is incorrect. It is intended to compensate for incorrectly configured servers but can cause a lot of harm obviously. Thus, even if you always send mime types, this is a good header to include.
Regarding X-XSS-Protection, I'm afraid you have also been slightly misinformed, or it's your wording I'm misinterpreting. XSS isn't for sites explicitly allowing the uploading of Javascript. XSS is abusing a sites input fields to include unescaped javascript or html in an otherwise benign input field.
To summarize, all these headers give you added protection for free and the reasons you give for not enabling them are unfortunately flawed / misinformed.
even for someone who doesn't know like 'nothing' html/web related.
i encourage you to post this on the tor-dev-list (register with a throw-away-acc). its worth a discussion and valuable because you can provide detailed logs and know-how.
besides that... i would look into, how the big onion-markets (as listed at dnstats.net) mitigate those kind of attacks... just as a hint
(*make kaputt, what makes you kaputt - jesus*)
- https://temp-mail.org
- https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-dev
- https://dnstats.net
Well done! Please check
https://metrics.torproject.org/userstats-relay-country.html?start=2017-04-01&end=2017-05-08&country=tw&events=off
NOTE: We tracked Eddie to servers in/near France and Germany. Taiwan doesn't sound right. Both Germany and France had so much traffic during that time, that an additional 10,000 connections wouldn't make a dent on their graphs.
Using either ip tables from a script trigger to send the malicious traffic to a black hole, log it and forget about it.
Or
Use something like nginx for a reverse proxy from a scripted trigger to send the traffic to a honeypot and have some serious fun..
Either way sounds like an interesting information gathering "opportunity".
Hope this adds to your premise and not detract.
obv not linked to userland daemon.
but shims could be added to controller.
tor still hasn't implemented display of per circuit far end pubkeys.
whois -h whois.ripe.net -B -T inetnum -r -L 185.170.41.7
for your whois query -- the above shows the chain of less to more specific objects, from the whole IPv4 address space, through to the allocation to RIPE, the allocation from RIPE, and the likely bogus assignment from the RIPE member.
Unfortunately, you provided me with no information that can be used to diagnose or debug your problem. And you provided me with no means to follow-up with you.
On May 9, at roughly 11pm local time (8am Moscow time), the Internet Archive came under another denial of service attack. This attack is from Eddie v2. I have been able to mitigate much of the attack, but I have been unable to stop it. In addition, two different versions of Dennis have been attacking the site. (Fortunately, I managed to fend off Freddie the Java bot for the time being.)
Until the attacks stop, transfers of large data file are likely to timeout.
In addition, the Tor Project has not responded to my queries about how to report two different DoS attacks that happen due to the tor daemon.
http://ia802300.us.archivecrfip2lpi.onion/27/items/oldclockswatches00brit/oldclockswatches00brit.pdf
Indeed I get a time out:
Operation timed out after 19994 milliseconds with 20971189 out of 61561010 bytes received
This is a known problem -- due to the slow transfer rate between IA and the hidden service. (The problem is made worse and more noticeable by the DoS bots.) However, I think I may have a workaround! I'll be working on it this weekend.
Did you try to ask in the TOR-TALK mailing list? https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-talk
With every other commercial, open source, and private group that I have worked with, they have NOT wanted security risks exposed in public forums.
There are best practices used in the industry for reporting security-related issues. I am following these best practices. These include ISO/IEC 29147:2014 (from 2014), as well as common best practices from 2006 (https://www.first.org/resources/papers/tc-jan2006/flanagan-tara-slides.pdf), 2004 (https://www.dhs.gov/xlibrary/assets/vdwgreport.pdf), 2002 (https://tools.ietf.org/html/draft-christey-wysopal-vuln-disclosure-00) ... They all basically say the same thing:
1. Vendors need a well-defined contact point; no scavenger hunts.
2. People reporting security issues (like me) should use the well-defined contact points. As noted on the Tor Project's Contact page, the official contact method is to use their LDAP service. But the LDAP service does not identify who is responsible for what. The contact page also specifies contacting them on Twitter -- I did that, and was directed to both the LDAP page and to their non-existent/non-reponsive security mailing list.
When failing to reach the security contact point, I went public. Again, this is a standard and best practice.
Why didn't I use IRC or one of the Tor Project's mailing lists? Four reasons:
1. I didn't know about them at the time.
2. I haven't used IRC in a decade -- what a throwback to the 1993! With IRC, you don't know who you're talking to. The person may claim to work on the IRC project, but may actually be an impersonator or hostile entity. And you have no idea who is lurking and observing the conversation. This is why it's always best to only communicate with official contact points.
3. I don't like signing up for a service in order to report a vulnerability. To post on the mailing lists, you need to sign up. Signing up means spam; I hate spam.
4. Any disclosure on those public forums (unofficial contact points) is no different than going public. And without reporting to a wider audience, a limited public disclosure is more likely to help bad guys than good guys.
Oh! How to kill those circuits. I don't know how to kill them. If I knew, I'd post it.
I have spoken with some tor developers (who are not part of the Tor Project) -- they are working out how to do it on their own, but no ETA.
The Tor Project's developers are non-responsive. My emails to them have gone unanswered. And if they don't answer emails from their LDAP accounts, then there's no reason to assume that they will answer emails from a mailing list or requests from an IRC channel.
You said May 9th ? Beat me but please look again at:
https://metrics.torproject.org/userstats-relay-country.html?start=2017-04-01&end=2017-05-12&country=tw&events=off
Why is there a break in the graph from May 6-8? This same break is seen with every other country. Assuming there is a straight line between the missing data points, there is no indication of a drop or re-appearance associated with Eddie.
Also, my previous reply still holds: This is only a difference of 10,000 connections. If this were compared as the same scale as Germany or France, it would be a blip since they handle over 100,000 connections per day.
> Why is there a break in the graph from May 6-8?
May-be the metrics backend was down for two days.
> Also, my previous reply still holds: This is only a difference of 10,000
> connections. If this were compared as the same scale as Germany or France,
> it would be a blip since they handle over 100,000 connections per day.
A 'connection' is a suggestion about a connecting IP to the network:
https://metrics.torproject.org/userstats-relay-country.html
This graph shows the estimated number of directly-connecting clients;
that is, it excludes clients connecting via bridges. These estimates are
derived from the number of directory requests counted on directory
authorities and mirrors. Relays resolve client IP addresses to country
codes, so that graphs are available for most countries. Furthermore, it
is possible to display indications of censorship events as obtained from
an anomaly-based censorship-detection system (for more details, see this
technical report). For further details see these questions and answers
about user statistics.
One connection can create several or hundreds of circuits:
https://gitweb.torproject.org/metrics-web.git/tree/doc/users-q-and-a.txt
Q: How do you get from these directory requests to user numbers?
A: We put in the assumption that the average client makes 10 such requests
per day. A tor client that is connected 24/7 makes about 15 requests per
day, but not all clients are connected 24/7, so we picked the number 10
for the average client. We simply divide directory requests by 10 and
consider the result as the number of users. Another way of looking at it,
is that we assume that each request represents a client that stays online
for one tenth of a day, so 2 hours and 24 minutes.
Unfortunately it's unsurprising you'd attract resourceful adversaries, hopefully the Tor Project decides to respond to your concerns.