 Yesterday at the WWDC keynote, Apple announced a series of new security and privacy features, including one feature that’s drawn a bit of attention — and confusion. Specifically, Apple announced that they will be using a technique called “Differential Privacy” (henceforth: DP) to improve the privacy of their data collection practices.
Yesterday at the WWDC keynote, Apple announced a series of new security and privacy features, including one feature that’s drawn a bit of attention — and confusion. Specifically, Apple announced that they will be using a technique called “Differential Privacy” (henceforth: DP) to improve the privacy of their data collection practices.The reaction to this by most people has been a big “???”, since few people have even heard of Differential Privacy, let alone understand what it means. Unfortunately Apple isn’t known for being terribly open when it comes to sharing the secret sauce that drives their platform, so we’ll just have to hope that at some point they decide to publish more. What we know so far comes from Apple’s iOS 10 Preview guide:
Starting with iOS 10, Apple is using Differential Privacy technology to help discover the usage patterns of a large number of users without compromising individual privacy. To obscure an individual’s identity, Differential Privacy adds mathematical noise to a small sample of the individual’s usage pattern. As more people share the same pattern, general patterns begin to emerge, which can inform and enhance the user experience. In iOS 10, this technology will help improve QuickType and emoji suggestions, Spotlight deep link suggestions and Lookup Hints in Notes.
While we don’t have those details, this seems like a good time to at least talk a bit about what Differential Privacy is, how it can be achieved, and what it could mean for Apple — and for your iPhone.
The motivation
In the past several years, “average people” have gotten used to the idea that they’re sending a hell of a lot of personal information to the various services they use. Surveys also tell us they’re starting to feel uncomfortable about it.
This discomfort makes sense when you think about companies using our personal data to market (to) us. But sometimes there are decent motivations for collecting usage information. For example, Microsoft recently announced a tool that can diagnose pancreatic cancer by monitoring your Bing queries. Google famously runs Google Flu Trends. And of course, we all benefit from crowdsourced data that improves the quality of the services we use — from mapping applications to restaurant reviews.
Unfortunately, even well-meaning data collection can go bad. For example, in the late 2000s, Netflix ran a competition to develop a better film recommendation algorithm. To drive the competition, they released an “anonymized” viewing dataset that had been stripped of identifying information. Unfortunately, this de-identification turned out to be insufficient. In a well-known piece of work, Narayanan and Shmatikov showed that such datasets could be used to re-identify specific users — and even predict their political affiliation! — if you simply knew a little bit of additional information about a given user.
This sort of thing should be worrying to us. Not just because companies routinely share data (though they do) but because breaches happen, and because even statistics about a dataset can sometimes leak information about the individual records used to compute it. Differential Privacy is a set of tools that was designed to address this problem.
What is Differential Privacy?
Differential Privacy is a privacy definition that was originally developed by Dwork, Nissim, McSherry and Smith, with major contributions by many others over the years. Roughly speaking, what it states can summed up intuitively as follows:
Imagine you have two otherwise identical databases, one with your information in it, and one without it. Differential Privacy ensures that the probability that a statistical query will produce a given result is (nearly) the same whether it’s conducted on the first or second database.
One way to look at this is that DP provides a way to know if your data has a significant effect on the outcome of a query. If it doesn’t, then you might as well contribute to the database — since there’s almost no harm that can come of it. Consider a silly example:
Imagine that you choose to enable a reporting feature on your iPhone that tells Apple if you like to use the 💩 emoji routinely in your iMessage conversations. This report consists of a single bit of information: 1 indicates you like 💩 , and 0 doesn’t. Apple might receive these reports and fill them into a huge database. At the end of the day, it wants to be able to derive a count of the users who like this particular emoji.
It goes without saying that the simple process of “tallying up the results” and releasing them does not satisfy the DP definition, since computing a sum on the database that contains your information will potentially produce a different result from computing the sum on a database without it. Thus, even though these sums may not seem to leak much information, they reveal at least a little bit about you. A key observation of the Differential Privacy research is that in many cases, DP can be achieved if the tallying party is willing to add random noise to the result. For example, rather than simply reporting the sum, the tallying party can inject noise from a Laplace or gaussian distribution, producing a result that’s not quite exact — but that masks the contents of any given row. (For other interesting functions, there are many other techniques as well.)
Even more usefully, the calculation of “how much” noise to inject can be made without knowing the contents of the database itself (or even its size). That is, the noise calculation can be performed based only on knowledge of the function to be computed, and the acceptable amount of data leakage.
A tradeoff between privacy and accuracy
Now obviously calculating the total number of 💩 -loving users on a system is a pretty silly example. The neat thing about DP is that the same overall approach can be applied to much more interesting functions, including complex statistical calculations like the ones used by Machine Learning algorithms. It can even be applied when many different functions are all computed over the same database.
But there’s a big caveat here. Namely, while the amount of “information leakage” from a single query can be bounded by a small value, this value is not zero. Each time you query the database on some function, the total “leakage” increases — and can never go down. Over time, as you make more queries, this leakage can start to add up.
This is one of the more challenging aspects of DP. It manifests in two basic ways:
- The more information you intend to “ask” of your database, the more noise has to be injected in order to minimize the privacy leakage. This means that in DP there is generally a fundamental tradeoff between accuracy and privacy, which can be a big problem when training complex ML models.
- Once data has been leaked, it’s gone. Once you’ve leaked as much data as your calculations tell you is safe, you can’t keep going — at least not without risking your users’ privacy. At this point, the best solution may be to just to destroy the database and start over. If such a thing is possible.
The total allowed leakage is often referred to as a “privacy budget”, and it determines how many queries will be allowed (and how accurate the results will be). The basic lesson of DP is that the devil is in the budget. Set it too high, and you leak your sensitive data. Set it too low, and the answers you get might not be particularly useful.
Now in some applications, like many of the ones on our iPhones, the lack of accuracy isn’t a big deal. We’re used to our phones making mistakes. But sometimes when DP is applied in complex applications, such as training Machine Learning models, this really does matter.
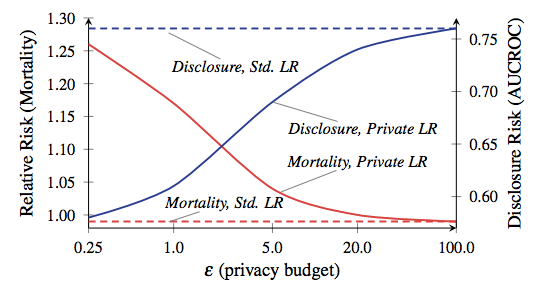 |
| Mortality vs. info disclosure, from Frederikson et al. The red line is partient mortality. |
To give an absolutely crazy example of how big the tradeoffs can be, consider this paper by Frederikson et al. from 2014. The authors began with a public database linking Warfarin dosage outcomes to specific genetic markers. They then used ML techniques to develop a dosing model based on their database — but applied DP at various privacy budgets while training the model. Then they evaluated both the information leakage and the model’s success at treating simulated “patients”.
The results showed that the model’s accuracy depends a lot on the privacy budget on which it was trained. If the budget is set too high, the database leaks a great deal of sensitive patient information — but the resulting model makes dosing decisions that are about as safe as standard clinical practice. On the other hand, when the budget was reduced to a level that achieved meaningful privacy, the “noise-ridden” model had a tendency to kill its “patients”.
Now before you freak out, let me be clear: your iPhone is not going to kill you. Nobody is saying that this example even vaguely resembles what Apple is going to do on the phone. The lesson of this research is simply that there are interesting tradeoffs between effectiveness and the privacy protection given by any DP-based system — these tradeoffs depend to a great degree on specific decisions made by the system designers, the parameters chosen by the deploying parties, and so on. Hopefully Apple will soon tell us what those choices are.
How do you collect the data, anyway?
You’ll notice that in each of the examples above, I’ve assumed that queries are executed by a trusted database operator who has access to all of the “raw” underlying data. I chose this model because it’s the traditional model used in most of the literature, not because it’s a particularly great idea.
In fact, it would be worrisome if Apple was actually implementing their system this way. That would require Apple to collect all of your raw usage information into a massive centralized database, and then (“trust us!”) calculate privacy-preserving statistics on it. At a minimum this would make your data vulnerable to subpoenas, Russian hackers, nosy Apple executives and so on.
Fortunately this is not the only way to implement a Differentially Private system. On the theoretical side, statistics can be computed using fancy cryptographic techniques (such as secure multi-party computation or fully-homomorphic encryption.) Unfortunately these techniques are probably too inefficient to operate at the kind of scale Apple needs.
A much more promising approach is not to collect the raw data at all. This approach was recently pioneered by Google to collect usage statistics in their Chrome browser. The system, called RAPPOR, is based on an implementation of the 50-year old randomized response technique. Randomized response works as follows:
- When a user wants to report a piece of potentially embarrassing information (made up example: “Do you use Bing?”), they first flip a coin, and if the coin comes up “heads”, they return a random answer — calculated by flipping a second coin. Otherwise they answer honestly.
- The server then collects answers from the entire population, and (knowing the probability that the coins will come up “heads”), adjusts for the included “noise” to compute an approximate answer for the true response rate.
Intuitively, randomized response protects the privacy of individual user responses, because a “yes” result could mean that you use Bing, or it could just be the effect of the first mechanism (the random coin flip). More formally, randomized response has been shown to achieve Differential Privacy, with specific guarantees that can adjusted by fiddling with the coin bias.
 |
| I’ve met Craig Federighi. He actually looks like this in person. |
While there’s no hard evidence that Apple is using a system like RAPPOR, there are some small hints. For example, Apple’s Craig Federighi describes Differential Privacy as “using hashing, subsampling and noise injection to enable…crowdsourced learning while keeping the data of individual users completely private.” That’s pretty weak evidence for anything, admittedly, but presence of the “hashing” in that quote at least hints towards the use of RAPPOR-like filters.
The main challenge with randomized response systems is that they can leak data if a user answers the same question multiple times. RAPPOR tries to deal with this in a variety of ways, one of which is to identify static information and thus calculate “permanent answers” rather than re-randomizing each time. But it’s possible to imagine situations where such protections could go wrong. Once again, the devil is very much in the details — we’ll just have to see. I’m sure many fun papers will be written either way.
So is Apple’s use of DP a good thing or a bad thing?
As an academic researcher and a security professional, I have mixed feelings about Apple’s announcement. On the one hand, as a researcher I understand how exciting it is to see research technology actually deployed in the field. And Apple has a very big field.
On the flipside, as security professionals it’s our job to be skeptical — to at a minimum demand people release their security-critical code (as Google did with RAPPOR), or at least to be straightforward about what it is they’re deploying. If Apple is going to collect significant amounts of new data from the devices that we depend on so much, we should really make sure they’re doing it right — rather than cheering them for Using Such Cool Ideas. (I made this mistake already once, and I still feel dumb about it.)
But maybe this is all too “inside baseball”. At the end of the day, it sure looks like Apple is honestly trying to do something to improve user privacy, and given the alternatives, maybe that’s more important than anything else.

Great article!
+1
Very insightful article, thanks.
I'm sure the specifics will be outlined in the iOS security white paper once it gets updated for iOS 10. That's where they usually release the juicy info.
“DP”… ha!!
Nice write-up and research.!!!
The alternative is Google collecting all your data to sell to advertisers and the NSA.
Great article, this is a crucial topic for the future of privacy. There is also a Quora Knowledge Prize on differential privacy running right now, some very cool answers what it is and why it's so important to understand for users: https://www.quora.com/What-are-the-limitations-of-Apple%E2%80%99s-%E2%80%9Cdifferential-privacy%E2%80%9D-approach-to-collecting-user-data/answer/Joh-Bhakdi?srid=kpq
That's one alternative. If you don't trust Google or Apple, don't use either. eBay is full of old Nokias.
My thoughts exactly… maybe we shouldn't be calling it “DP” ��
This comment has been removed by the author.
“Fortunately this is not the only way to implement a Differentially Private system. On the theoretical side, statistics can be computed using fancy cryptographic techniques (such as secure multi-party computation or fully-homomorphic encryption.) Unfortunately these techniques are probably too inefficient to operate at the kind of scale Apple needs. “
What does this really mean ? DP and FHE solve different problems. If Apple/Google applied FHE on collected data and found the usage patterns does not necessarily prevent the breach of privacy of individual. Data Privacy(achieved via blindfolded computations of FHE) is different from Individual's Privacy(hiding a person in the crowd). DP computed on encrypted data using FHE does not provide any better privacy for individual.
On an other hand. Actually DP does not provide any privacy at all for many attributes of the individual. (For example : How do we hide the gender using DP ? what statistically noise can be added to hide it ? ). Any privacy techniques like the netflix or rainbow car rentals or AOL web logs are broken using humungous auxiliary data available publicly. (For example Netflix case is broken by IMDB ratings ). Similarly what ever privacy apple or google using DP or similar could be easily broken by them based on vast public data on the Internet.
“How do we hide the gender using DP ? what statistically noise can be added to hide it ?”
Why would that be more difficult than hiding if you're a �� lover?
Same way as you would protect the privacy of ��-lovers. If you are tallying the number of M/F in a population, add noise scaled to the sensitivity of the query (1, in this case).
“Similarly what ever privacy apple or google using DP or similar could be easily broken by them based on vast public data on the Internet.”
No, it could not. Done right, differential privacy guarantees are not broken by any amount of background knowledge.
The point of DP is that not even apple see the private data… the statistical noise is added on the device before being sent up. FHE requires one “trusted” body (Apple, or whomever) to collect the data in the raw, process it and release the aggregated, non-private data.
Privacy of DP is bounded by number of queries we can ask the system and amount of info publicly available. Lets do this to a DP system, Give me all M in the population ? (Gives count+noise) . Now Give me all the M in the population with pincode ? (Gives count+noise). Give me all the M in the population with pincode and has Ferrari (Count + noise). Now goto facebook and see who in the pincode has a Ferrari ! With very good probability you can determine who it is. All privacy could be broken by inferential attacks available on public sources like linkedin/facebook/google/blogs. Either shared by us or our friends or our competitors with our without our consent. Privacy is a lost game, am sorry.
@Chris, The challenge with DP is finding the right amount of noise to retain some utility in the data without losing the privacy. If the noise is too low we can breach privacy , if it is too high the data is useless.
Also If Apple is the trusted body to collect and aggregate the data we don't need FHE ! FHE is to avoid trusted bodies for data computations. Also not always aggregated data is not non-private data. Repeat about the queries to the system (without noise).
“What does this really mean ? DP and FHE solve different problems.”
Not necessarily. FHE provides a means to compute functions over encrypted data. For example, users could encrypt their database entries and allow Apple to compute some function over those encrypted entries, at which point someone could decrypt the aggregate result.
But this doesn't really solve the original problem that Differential Privacy addresses, which is that the statistical results themselves can leak information about the underlying records. My point here is that FHE offers a potential solution to the computation and data collection problem, but does not allow you to work with (decrypted, aggregate) results without risking privacy. Differential Privacy addresses that last piece.
This slide deck might shed some light on this, starting at slide 62:
http://devstreaming.apple.com/videos/wwdc/2016/709tvxadw201avg5v7n/709/709_engineering_privacy_for_your_users.pdf
Great article, thanks.
Two points:
1- In the ‘killing patients’ example (I won't read it) what is the effects of ‘quantity.’
A common sense about machine learning is the it need huge amounts of data.
So, the cited relation between privacy and accuracy will probably be affected by the number of events.
2- As far as I understood the presentations, DF is made within the device. Now raw data goes to Apple's servers.
It’s not only the repeated query attack that leaks information in randomized response techniques. If each bit in a vector of n bits is a function of k bits, n>k, the vector could be an error correcting code and the randomized vector a received coded string, which can be decided to obtain the original k bits. This works even when the vector is not a function of the k bits but simply has large mutual information with the k bits. See,for example, https://www.seas.gwu.edu/~poorvi/InferenceAttacks.pdf