
Zero downtime upgrade with Ansible and HAProxy
![]() Some of you may not be familiar with the terms “Rolling upgrade” or “Rolling restart". This is the action of upgrading or restarting a cluster without service interruption (alias zero downtime). In most cases, this is done node by node, but in fact it depends of the technology you’re managing and the number of active nodes in your cluster.
Some of you may not be familiar with the terms “Rolling upgrade” or “Rolling restart". This is the action of upgrading or restarting a cluster without service interruption (alias zero downtime). In most cases, this is done node by node, but in fact it depends of the technology you’re managing and the number of active nodes in your cluster.
At Nousmotards we have several Java Spring Boot applications running. Restarting one application can take up to 1 min. During that time, the service was down which is a shame when you make multiple deployments during per day. To avoid this, I’ve wrote an Ansible playbook to perform a rolling upgrade with the help of HAProxy. I’m going to share it with you and explain in details how it works.
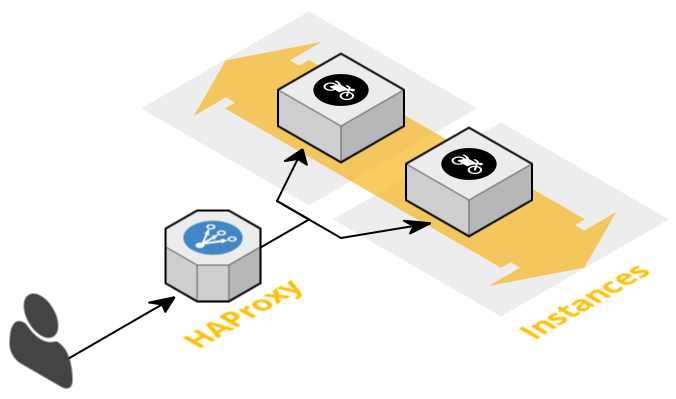
First of all, you need to understand our infrastructure. Regarding our Java micro services, each one is running at least two instances and a load balancer is in front in active/active mode. All our applications are stateless which help us to avoid taking care of the data. Here is a simplified example of our infrastructure for a single Java app:
---
- hosts: "{{nm_app}}"
user: root
serial: 1
any_errors_fatal: TrueHere you can see the hosts parameter as a variable (nm_app is the name of the application and the container dns name as well) because I don’t want something specific but applicable to any kind of application. This variable is in fact a group of machines pulled out from Consul (it can be from a flat file).
The serial means that it should not perform those tasks on several hosts in parallel (limit to 1 host at a time). If you’ve got a large set of machines, you can define a percentage. This will stop upgrading/restarting if it fails at some point.
The any_errors_fatal parameter ensures me that it will stop if an issue occur. I personally prefer to manually repair the issue in case of a failure rather than putting the service down and perform a full restart. It’s a security option.
pre_tasks:
- name: read haproxy config to catch if nm app is available
shell: 'echo "show stat" | socat {{haproxy_socks}} stdio | grep -c "^{{nm_app}}"'
delegate_to: "{{ srv_role_location[nm_app] }}"
ignore_errors: true
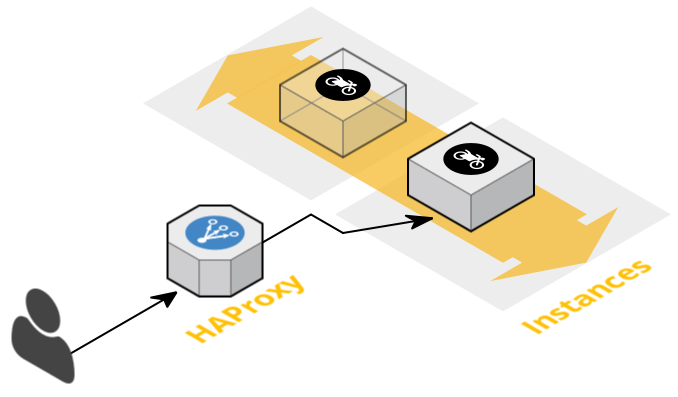
register: app_in_haproxyHere I’m running pre_tasks to get out the application from Haproxy (meaning setting it in maintenance mode, so no new connections will be established on this application). For this first task, I just want to be sure that the application I’m requesting is registered in Haproxy to avoid playbook failure during next steps.
Of course, Haproxy is not on the same host as the application, that’s why I’m using the delegate_to parameter pointing to a dictionary with the host information of the application (which, in my case, is running inside a Docker container but can be triggered from anywhere like Consul kv).
The result is stored in the app_in_haproxy variable. Now the idea is to set Haproxy for this current host in maintenance mode and stop the service to get something like this:
- name: disabling application on the load balancer
haproxy:
host: "{{ ansible_nodename }}"
socket: "{{ haproxy_socks }}"
state: disabled
delegate_to: "{{ srv_role_location[nm_app] }}"
when: app_in_haproxy.stdout != '0'
- name: disabling application on monit
command: "monit stop {{nm_app}}"
register: monit_stop_result
until: monit_stop_result.rc == 0
retries: 120
delay: 10I’m using Monit to manage the services inside Docker. That’s why I stop the service managed by Monit (Note that I’m not using the monit module in Ansible because it’s buggy). Then I’m waiting for the port application to be closed. That way, I’m sure it will be gracefully stopped and no clients will be connected anymore:
- name: Waiting application to be stopped
wait_for:
host: '127.0.0.1'
port: "{{nm_java_apps_params[nm_app]['port']}}"
state: stopped
delay: 1
timeout: 1200Now I’m calling a role that will ensure my application is installed with the good version. If it’s not the case, it will perform the upgrade:
roles:
- role: java-application
app_name: "{{nm_app}}"
enable_monit_restart: falseWhen finished, the new application is deployed. We can now start everything in reverse order:
post_tasks:
- name: enabling application on monit
command: "monit start {{nm_app}}"
register: monit_start_result
until: monit_start_result.rc == 0
retries: 120
delay: 10
- name: Waiting application to be up
wait_for:
host: '127.0.0.1'
port: "{{nm_java_apps_params[nm_app]['port']}}"
state: started
delay: 1
timeout: 1200
- name: enabling application on the load balancer
haproxy:
host: "{{ ansible_nodename }}"
socket: "{{ haproxy_socks }}"
state: enabled
delegate_to: "{{srv_role_location.nm_app}}"
when: app_in_haproxy.stdout != '0'To be sure Haproxy had enough time to switch to the green state, I’m triggering the state for 20s and only continue when green. This is normally not necessary but a useful guaranty tip:
- name: waiting haproxy to be green
shell: 'echo "show stat" | socat {{haproxy_socks}} stdio | grep {{ansible_hostname}} | grep -c UP'
register: haproxy_green
until: haproxy_green.stdout != 1
retries: 20
delay: "1"
delegate_to: "{{ srv_role_location[nm_app] }}"
when: app_in_haproxy.stdout != '0'This host is now delivering the latest version of the application, Ansible will now continue with the others hosts one by one:
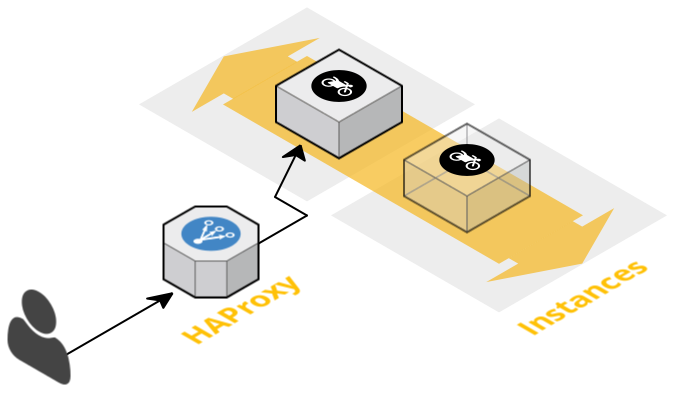
When finished, all apps are upgraded without any downtime and no stress.
This kind of solution is not new, but with the help of Ansible, it becomes really easy.
