
If you sit a group of cryptographers down and ask them whether TLS is provably secure, you’re liable to get a whole variety of answers. Some will just giggle. Others will give a long explanation that hinges on the definitions of ‘prove‘ and ‘secure‘. What you will probably not get is a clear, straight answer.
In fairness, this is because there is no clear, straight answer. Unfortunately, like all the things you really need to know in life, it’s complicated.
Still, just because something’s complicated doesn’t mean that we get to ignore it. And the security of TLS is something we really shouldn’t ignore — because TLS has quietly become the most important and trusted security protocol on the Internet. While plenty of security experts will point out the danger of improperly configured TLS setups, most tend to see (properly configured) TLS as a kind of gold standard — and it’s now used in all kinds of applications that its designers would probably never have envisioned.
And this is a problem, because (as Marsh points out) TLS (or rather, SSL) was originally designed to secure $50 credit card transactions, something it didn’t always do very well. Yes, it’s improved over the years. On the other hand, gradual improvement is no substitute for correct and provable security design.
All of which brings us to the subject of this — and subsequent — posts: even though TLS wasn’t designed to be a provably-secure protocol, what can we say about it today? More specifically, can we prove that the current version of TLS is cryptographically secure? Or is there something fundamental that’s holding it back?
The world’s briefest overview of TLS
If you’re brand new to TLS, this may not be the right post for you. Still, if you’re looking for a brief refresher, here it is:
TLS is a protocol for establishing secure (Transport layer) communications between two parties, usually denoted as a Client and a Server.
The protocol consists of several phases. The first is a negotiation, in which the two peers agree on which cryptographic capabilities they mutually support — and try to decide whether a connection is even possible. Next, the parties engage in a Key Establishment protocol that (if successful) authenticates one or both of the parties, typically using certificates, and allows the pair to establish a shared Master Secret. This is done using a handful of key agreement protocols, including various flavors of Diffie-Hellman key agreement and an RSA-based protocol.
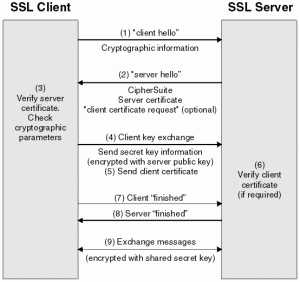 |
| Overview of TLS (source) |
So why can’t we prove it secure?
TLS sounds very simple. However, it turns out that you run into a few serious problems when you try to assemble a security proof for the protocol. Probably the most serious holdup stems from the age of the cryptography used in TLS. To borrow a term from Eric Rescorla: TLS’s crypto is downright prehistoric.
This can mostly be blamed on TLS’s predecessor SSL, which was designed in the mid-90s — a period better known as ‘the dark ages of industrial crypto‘. All sorts of bad stuff went down during this time, much of which we’ve (thankfully) forgotten about. But TLS is the exception! Thanks to years of backwards compatibility requirements, it’s become a sort of time capsule for all sorts of embarrassing practices that should have died a long slow death in a moonlit graveyard.
For example:
- The vast majority of TLS handshakes use an RSA padding scheme known as PKCS#1v1.5. PKCS#1v1.5 is awesome — if you’re teaching a class on how to attack cryptographic protocols. In all other circumstances it sucks. The scheme was first broken all the way back in 1998. The attacks have gotten better since.
- The (AES)-CBC encryption used by SSL and TLS 1.0 is just plain broken, a fact that was recently exploited by the BEAST attack. TLS 1.1 and 1.2 fix the glaring bugs, but still use non-standard message authentication techniques, that have themselves been attacked.
- Today — in the year 2012 — the ‘recommended’ patch for the above issue is to switch to RC4. Really, the less said about this the better.
Although each of these issues have all been exploited in the past, I should be clear that current implementations do address them. Not by fixing the bugs, mind you — but rather, by applying band-aid patches to thwart the known attacks. This mostly works in practice, but it makes security proofs an exercise in frustration.
The second obstacle to proving things about TLS is the sheer complexity of the protocol. In fact, TLS is less a ‘protocol’ than it is a Frankenstein monster of of options and sub-protocols, all of which provide a breeding ground for bugs and attacks. Unfortunately, the vast majority of academic security analyses just ignore all of the ‘extra junk’ in favor of addressing the core crypto. Which is good! But also too bad — since these options where practically every real attack on TLS has taken place.
Lastly, it’s not clear quite which definition of security we should even use in our analysis. In part this is because the TLS specification doesn’t exactly scream ‘I want to be analyzed‘. In part it’s because definitions have been evolving over the years.
So you’re saying TLS is unprovable?
No. I’m just lowering expectations.
The truth is there’s a lot we do know about the security of TLS, some of it surprisingly positive. Several academic works have even given us formal ‘proofs’ of certain aspects of the protocol. The devil here lies mainly in the definitions of ‘proof‘ and — worryingly — ‘TLS‘.
For those who don’t live for the details, I’m going to start off by listing a few of the major known results here. In no particular order, these are:
- If properly implemented with a secure block cipher, the TLS 1.1/1.2 record encryption protocol meets a strong definition of (chosen ciphertext attack) security. Incidentally, the mechanism is also capable of hiding the length of the encrypted records. (Nobody even bothers to claim this for TLS 1.0 — which everybody agrees is busted.)
- A shiny new result from CRYPTO 2012 tells us that (a stripped-down version of) the Diffie-Hellman handshake (DHE) is provably secure in the ‘standard model’ of computation. Moreover, combined with result (1), the authors prove that TLS provides a secure channel for exchanging messages. Yay!This result is important — or would be, if more people actually used DHE. Unfortunately, at this point more people bike to work with their cat than use TLS-DHE.
- At least two excellent works have tackled the RSA-based handshake, which is the one most people actually use. Both works succeed in proving it secure, under one condition: you don’t actually use it! To be more explicit: both proofs quietly replace the PKCS#v1.5 padding (in actual use) with something better. If only the real world worked this way.
- All is not lost, however: back in 2003 Jonnson and Kaliski were able to prove security for the real RSA handshake without changing the protocol. Their proof is in the random oracle model (no biggie), but unfortunately it requires a new number-theoretic hardness assumption that nobody has talked about or revisited since. In practice this may be fine! Or it may not be. Nobody’s been able to investigate it further, since every researcher who tried to look into it… wound up dead. (No, I’m just kidding. Although that would be cool.)
- A handful of works have attempted to analyze the entirety of SSL or TLS using machine-assisted proof techniques. This is incredibly ambitious, and moreover it’s probably the only real way to tackle the problem. Unfortunately, the proofs hugely simplify the underlying cryptography, and thus don’t cover the full range of attacks. Moreover, only computers can read them.
While I’m sure there are some important results I’m missing here, this is probably enough to take us 95% of the way to the ‘provable’ results on TLS. What remains is the details.
And oh boy, are there details. More than I can fit in one post. So I’m going to take this one chunk at a time, and see how many it takes.
An aside: what are we trying to prove, anyway?
One thing I’ve been a bit fast-and-loose on is: what are we actually proving about these protocols in the first place, anyway? The question deserves at least a few words — since it’s received thousands in the academic literature.
One obvious definition of security can be summed up as ‘an attacker on the wire can’t intercept modify data’, or otherwise learn the key being established. But simply keeping the data secret isn’t enough; there’s also a matter of freshness. Consider the following attack:
- I record communications between a legitimate client and his bank’s server, in which the client requests $5,000 to be transferred from her account to mine.
- Having done this, I replay the client’s messages to the server a hundred times. If all goes well, I’m a whole lot richer.
Now this is just one example, but it shows that the protocol does require a bit of thinking. Taking this a step farther, we might also want to ensure that the master secret is random, meaning even if (one of) the Client or Server are dishonest, they can’t force the key to a chosen value. And beyond that, what we really care about is that the protocol data exchange is secure.
The RSA handshake
TLS supports a number of different ciphersuites and handshake protocols. As I said above, the RSA-based handshake is the most popular one — almost an absurd margin. Sure, a few sites (notably Google) have recently begun supporting DHE and ECDH across the board. For everyone else there’s RSA.
So RSA seems as good a place as any to start. Even better, if you ignore client authentication and strip the handshake down to its core, it’s a pretty simple protocol:

Clearly the ‘engine’ of this protocol is the third step, where the Client picks a random 48-byte pre-master secret (PMS) and encrypts it under the server’s key. Since the Master Secret is derived from this (plus the Client and Server Randoms), an attacker who can’t ‘break’ this encryption shouldn’t be able to derive the Master Key and thus produce the correct check messages at the bottom.
So now for the $10,000,000 question: can we prove that the RSA encryption secure? And the simple answer is no, we can’t. This is because the encryption scheme used by TLS is RSA-PKCS#1v1.5, which is not — by itself — provably secure.
Indeed, it’s worse than that. Not only is PKCS#1v1.5 not provably secure, but it’s actually provably insecure. All the way back in 1998 Daniel Bleichenbacher demonstrated that PKCS#1v1.5 ciphertexts can be gradually decrypted, by repeatedly modifying them and sending the modified versions to be decrypted. If the decryptor (the server in this case) reveals whether the ciphertext is correctly formatted, the attacker can actually recover the encrypted PMS.
0x 00 02 { at least 8 non-zero random bytes } 00 { two-byte length } { 48-byte PMS }
Modern SSL/TLS servers are wise to this attack, and they deal with it in a simple way. Following decryption of the RSA ciphertext they check the padding. If it does not have the form above, they select a random PMS and go forward with the calculation of the Master Secret using this bogus replacement value. In principle, this means that the server calculates a basically random key — and the protocol doesn’t fail until the very end.
In practice this seems to work, but proving it is tricky! For one thing, it’s not enough to treat the RSA encryption as a black box — all of these extra steps and the subsequent calculation of the Master Secret are now intimately bound up with the security of the protocol, in a not-necessarily-straightforward way.
There are basically two ways to deal with this. Approach #1, taken by Morrisey, Smart and Warinschi and Gajek et al., follows what I call the ‘wishful thinking‘ paradigm. Both show that if you modify the encryption scheme used in TLS — for example, by eliminating the ‘random’ encryption padding, or swapping in a CCA-secure scheme like RSA-OAEP — the handshake is secure under a reasonable definition. This is very interesting from an academic point of view; it just doesn’t tell us much about TLS.
Fortunately there’s also the ‘realist‘ approach. This is embodied by an older CRYPTO paper by Jonnson and Kaliski. These authors considered the entirety of the TLS handshake, and showed that (1) if you model the PRF (or part of it) as a random oracle, and (2) assume some very non-standard number-theoretic assumptions, and (more importantly) (3) the TLS implementation is perfect, then you can actually prove that the RSA handshake is secure.
This is a big deal!
Unfortunately it has a few problems. First, it’s highly inelegant, and basically depends on all the parts working in tandem. If any part fails to work properly — if for example, the server leaks any information that could indicate whether the encryption padding is valid or not — then the entire thing crashes down. That the combined protocol works is in fact, more an accident of fate than the result of any real security engineering.
Secondly, the reduction extremely ‘loose’. This means that a literal interpretation would imply that we should be using ginormous RSA keys, much bigger than we do today. We obviously don’t pay attention to this result, and we’re probably right not to. Finally, it requires that we adopt odd number-theoretic assumption involving a ‘partial-RSA decision oracle’, something that quite frankly, feels kind of funny. While we’re all guilty of making up an assumption from time to time, I’ve never seen this assumption either before or since, and it’s significant that the scheme has no straightforward reduction the RSA problem (even in the random oracle model), something we would get if we used RSA-OAEP.
If your response is: who cares — well, you may be right. But this is where we stand.
So where are we?
Good question. We’ve learned quite a lot actually. When I started this post my assumption was that TLS was going to be a giant unprovable mess. Now that I’m halfway through this summary, my conclusion is that TLS is, well, still mostly a giant mess — but one that smacks of potential.
Of course so far I’ve only covered a small amount of ground. We still have yet to cover the big results, which deal with the Diffie-Hellman protocol, the actual encryption of data (yes, important!) and all the other crud that’s in the real protocol.
But those results will have to wait until the next post: I’ve hit my limit for today.

>If properly implemented with a secure block cipher, the TLS 1.1/1.2 record encryption protocol meets a strong definition of (chosen ciphertext attack) security. Incidentally, the mechanism is also capable of hiding the length of the encrypted records. (Nobody even bothers to claim this for TLS 1.0 — everybody agrees that thing's busted.)
Interesting. Does that length-hiding encryption apply to TLS with RC4 as well? I guess not, because the standards don't define any kind of padding for stream ciphers.
Yes, to the best of my knowledge, padding only applies to block cipher modes.
And notably, padding at the record-level adds less than 256 bytes to application data that may be 2^14 bytes long.
So, not much length-hiding per record, but you can accumulate more over a stream.
> Having done this, I replay the client's messages to the server a hundred times. If all goes well, I'm a whole lot richer.
Is this really something that TLS _has to_ prevent?
TLS, as the name implies, is used to secure the transport of the data. Replaying a transaction is an attack against the application that handles that transaction and would also work over an unsecure connection. So it's something the application designer should prevent in any case.
I'm not saying that TLS _shouldn't_ prevent something like this, far from it. But is this really a _must_ requirement for the protocol when trying to prove its security or is it a nice-to-have feature?
Or maybe I'm focusing too much on theory and the simple answer is: in practice, it should! Always!
Well, it makes no sense to use TLS if your application has to provide replay protection and secrecy on its own 🙂
I enjoyed this post and am looking forward to the next installment(s)!
Why is PKCS1v1.5 provably insecure due to the Bleichenbacher attack, but OAEP is not similarly proven insecure by Manger's attack. They both rely on the server emitting a different type of error as the result of incorrectly formatted plaintexts after decryption…
Unfortunately, at this point more people bike to work with their cat than use TLS-DHE.
Well, that's something of an exaggeration: openssl s_client -connect http://www.google.com:443 < /dev/null | grep ECDHE
From what people have been saying, it looks like the ability to see the length of the records in combination with compression support is likely to be the source of the CRIME attack.
New attack that leverages SPDY protocol to break SSL
http://blog.skepticfx.com/2012/09/breaking-ssltls-with-spdy.html
Because OAEP can be implemented securely while PKCS #1v1.5 in the general case can't. By which I mean, there's a generic way to handle decryption errors in OAEP, but there's no generic way in PKCS#1v1.5. TLS uses a workaround that seems to work for this particular application, but would not apply to every possible use of the encryption scheme.
Thank you for the article, easy to read and informative. By the way, this is the best blog about crypto I found so far.
I think the authentication scheme is extremely weak. Maybe it was never intended to do what it is doing today
It is a very long post.But it all make sense. Specifically to the IT people.